Zookeeper入门
Zookeeper入门
小郭写文章的目的是总结复盘学过的知识点,方便以后查阅。
如果本文对您也有帮助,可以动动您的小手点个关注和赞再走呀。
一、前言
在小郭的工作经历中,每个公司基本都使用到了zookeeper。趁着最近有空,小郭想在此总结一下zookeeper的基本知识。
二、zookeeper简介
Apache ZooKeeper 是 Apache 软件基金会旗下的开源项目,是用于分布式应用程序的分布式开源协调服务。它被设计为易于编程,并使用以熟悉的文件系统目录树结构为基础的数据模型。它在 Java环境 中运行。
ZooKeeper 的设计: ZooKeeper 允许分布式进程通过共享的分层命名空间相互协调,该命名空间的结构类似于标准文件系统,命名空间由文件和目录组成,而这些组成单元在 ZooKeeper 术语中统称为 znodes。与专为存储而设计的传统文件系统不同,ZooKeeper 数据保存在内存中,这意味着 ZooKeeper 可以实现高吞吐量和低延迟。ZooKeeper 的设计非常重视高性能、高可靠性、严格有序的访问。ZooKeeper 的性能优秀,因此它完全可以用于大型分布式系统. 可靠性方面使其不会成为单点故障。严格有序的访问意味着可以在客户端实现复杂的同步原语。
下面针对zookeeper的一些特性展开简介。
1、集群角色
通常在分布式系统中,构成一个集群中的每一台机器都有一个自己的角色,最典型的集群模式就是 master/slave (主备模式)。在这种模式中,我们把能够处理写操作请求的机器称为 Master ,把所有通过异步复制方式获取最新数据,并提供读请求服务的机器称为 Slave 机器。
而 ZooKeeper 没有采用这种方式,ZooKeeper 引用了 Leader、Follower和 Observer 三个角色。ZooKeeper 集群中的所有机器通过选举的方式选出一个 Leader,Leader 可以为客户端提供读服务和写服务。除了 Leader 外,集群中还包括了 Follower 和 Observer 。Follower 和 Observer 都能够提供读服务,唯一区别在于,*Observer * 不参与 Leader 的选举过程,也不参与写操作的"过半写成功"策略,因此 Observer 可以在不影响写性能的情况下提升集群的读性能。
2、原子性
在Zookeeper中要么更新成功,要么失败,不存在只产生部分结果的情况。
3、高性能
**Zookeeper的速度非常快。**ZooKeeper 应用程序在数千台机器上运行,尤其是在读多写少的情况下,它的性能最佳,比率约为 10:1。
所使用的测试环境:
- ZooKeeper release 3.2
- 服务器 双核 2GHz Xeon, 两块 15K RPM 的 SATA, 一块作为 ZK 的日志, 快照写到系统盘
- 读写请求都是 1K
- "Servers" 表示提供服务的 ZK 服务器数量
- 接近 30 台其它服务器用来模拟客户端
- leader 配置成不接受客户端连接
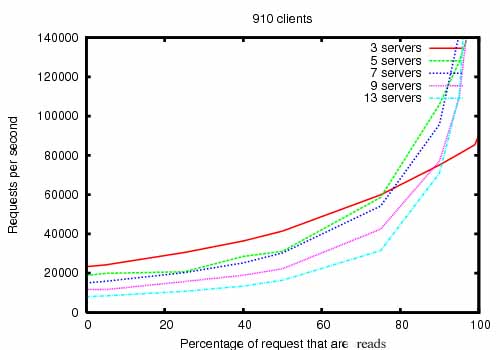
在读多写少的业务场景中,它的效率高。而写入操作由于涉及同步所有服务器的状态,性能会有一定影响。
4、高可靠
就像它协调的分布式应用程序一样,ZooKeeper 的部署本身也是多节点的,其中有且仅有一个Leader节点,组成 ZooKeeper 集群的服务器之间相互保持了解,并且它们在持久性存储中维护状态的内存映像,以及事务日志和快照信息。
通常情况下,只要大多数服务器可用,ZooKeeper 服务对外就是可用的。ZooKeeper 集群中,建议部署奇数个 ZooKeeper节点(或进程) —— 大多数情况下,3个节点就足够了。节点个数并不是越多越好 —— 节点越多,节点间通信所需的时间就会越久,选举 Leader 时需要的时间也会越久。
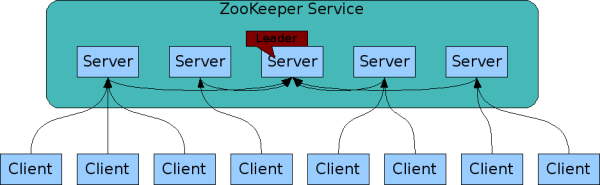
如上图所示,客户端只会连接到单个 ZooKeeper 服务器,在客户端维护了一个 TCP 连接,通过该连接发送请求、获取响应、获取监视事件和发送检测信号。如果与服务器的 TCP 连接中断,客户端将连接到其他服务器。
下面是官方对可靠性进行测试的数据结果:
运行了一个由 7 台机器组成的 ZooKeeper 服务。将写入百分比保持在恒定的 30%
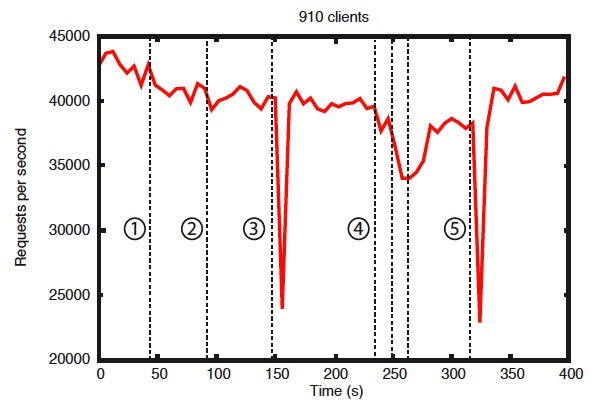
从上面的图中可以看出一些重要的观察结果。首先,如果followers失败并迅速恢复,那么即使发生故障,ZooKeeper 也能够维持高吞吐量。但也许更重要的是,领导者选举算法允许系统恢复得足够快,以防止吞吐量大幅下降。根据测试时的观察,ZooKeeper 只需不到 200 毫秒即可选出新的leader 。随着followers的恢复,一旦他们开始处理请求,ZooKeeper 就能够再次提高吞吐量。
5、顺序一致性
Zookeeper保证 来自客户端的更新将按发送顺序处理。
ZooKeeper 在每次更新时都会使用一个数字来标记,该数字反映了所有 ZooKeeper 事务的顺序。
6、数据模型和分层命名空间
数据模型
ZooKeeper 提供的命名空间与标准文件系统的命名空间非常相似。名称是一系列由斜杠 (/) 分隔的路径元素。ZooKeeper 命名空间中的每个节点都有路径标识。
分层命名空间
zookeeper的分层命名空间图:
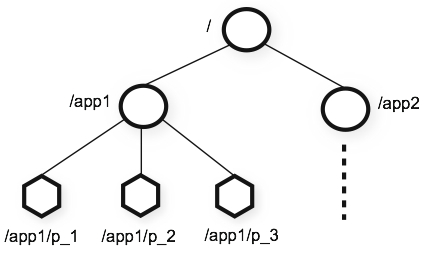
如上图所示,zookeeper的数据存储是分布在一个树上的不同的节点上的,官方术语使用 znode 来表示一个 ZooKeeper的 数据节点。
7、watch机制
watch:数据变更监听机制
客户端可以在 znode 上设置监听器,当 znode 发生变化时,将通知客户端并删除监听器,客户端会收到一个数据包,表示 znode 的数据发生了变化。
在3.6.0及以后的zookeeper版本中,客户端还可以在 znode 上设置永久的递归监听,这些监听在触发时不会被删除,并且会以递归方式触发已注册的 znode 以及任何子 znode 上的更改。
如果客户端与其中一个 ZooKeeper 服务器之间的连接断开,客户端将收到本地通知。
8、简单API接入
API主要是围绕对znode 的crud操作
ZooKeeper 的设计目标之一是提供一个非常简单的编程接口,而且有严格的ACL(权限)控制。因此,它仅支持以下操作:
- create : 在树中的某个位置创建znode
- delete : 删除一个znode
- exists : 判断树的某个位置是否存在节点
- get data : 读取某个节点的数据
- set data : 将数据写入某个节点
- get children : 检索节点的子节点列表
- sync : 等待数据传播
9、服务组件
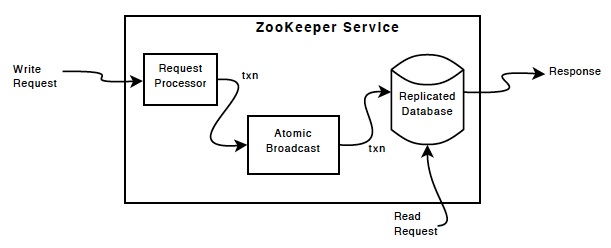
如上图所示,ZooKeeper Components 展现了ZooKeeper 服务的高级组件。除Request Processor(请求处理器)外,构成 ZooKeeper 服务的每个服务器都复制其自己的每个组件的副本。其中有个重要的高级组件是Replicated Database。
Replicated Database
Replicated Database是包含整个znode数据树的内存数据库。每一个更新操作都会先序列化到磁盘, 然后才会应用到内存数据库。
读写请求的区别如下:
- Read Request - ZK 服务器根据其服务内本地内存数据库来响应
- Write Request - ZK 服务器会将来自客户端的所有写请求转发到角色为 leader 的 ZK 服务器(leader 只有一个, 其它称为 follower或者Observer) 来写, 然后同步给 follower。
三、版本管理
1、版本管理策略
Apache ZooKeeper 社区同时支持两个发布分支:稳定版和当前版。ZooKeeper 的稳定版本为 3.8.x,当前版本为 3.9.x。一旦新的次要版本发布,稳定版本预计将很快退役,大约半年后将宣布生命周期结束。在半年的宽限期内,预计只会发布该版本的安全修复和关键修复。在宣布 EoL 后,社区不再提供进一步的补丁。
所有 ZooKeeper 版本都可以从官方 Apache 存档中访问。
2、版本历史
截止20231207,Apache ZooKeeper 3.9.1 是当前的版本,3.8.3 是最新的稳定版本。
小郭整理了每个已发布版本的信息:
| 版本 | 发行时间 | 备注 |
|---|---|---|
| ZooKeeper 3.9.1 | 2023.10.09 | 该版本是 3.9 分支的错误修复版本 |
| ZooKeeper 3.9.0 | 2023.08.03 | 该版本是 3.9 分支的第一个版本。 这是一个主要版本,它引入了许多新功能,最值得注意的是: 1)用于拍摄快照和流出数据的管理服务器 API 2)传达触发 WatchEvent 触发的 Zxid 3)TLS - 客户端信任/密钥存储的动态加载 4)添加 Netty-TcNative OpenSSL 支持 5)向 Zktreeutil 添加 SSL 支持 6)提高 syncRequestProcessor 性能 7)更新所有第三方依赖项,以消除所有已知的 CVE。 |
| ZooKeeper 3.8.3 | 2023.10.09 | 该版本是 3.8 分支的错误修复版本。 |
| ZooKeeper 3.8.2 | 2023.07.18 | 该版本是 3.8 分支的错误修复版本。 |
| ZooKeeper 3.8.1 | 2023.01.30 | 该版本是 3.8 分支的错误修复版本。 |
| ZooKeeper 3.8.0 | 2022.03.07 | 该版本是 3.8 分支的第一个版本。 这是一个主要版本,它引入了许多新功能,最值得注意的是: 1)将日志记录框架从 Apache Log4j1 迁移到 LogBack 2)从文件中读取密钥/信任存储密码(以及其他与安全相关的改进) 3)恢复了对OSGI的支持 4)减少了 Prometheus 指标对性能的影响 5)官方支持 JDK17(所有测试均通过) 6)更新所有第三方依赖项,以消除所有已知的 CVE。 |
| ZooKeeper 3.7.2 | 2023.10.09 | 该版本是 3.7 分支的错误修复版本。 |
| ZooKeeper 3.7.1 | 2022.05.12 | 该版本是 3.7 分支的错误修复版本。 它修复了 64 个问题,包括多个 CVE 修复。 |
| ZooKeeper 3.7.0 | 2021.03.27 | 该版本是 3.7 分支的第一个版本。 它引入了许多新功能,特别是: 1)从 Java 启动 ZooKeeper 服务器的 API (ZOOKEEPER-3874); 2)配额强制执行 (ZOOKEEPER-3301); 3)仲裁 SASL 身份验证中的主机名规范化 (ZOOKEEPER-4030); 4)支持 BCFKS 密钥/信任存储格式 (ZOOKEEPER-3950); 5)强制身份验证方案的选择 (ZOOKEEPER-3561); 6)“whoami”API 和 CLI 命令 (ZOOKEEPER-3969); 7)禁用摘要式身份验证的可能性 (ZOOKEEPER-3979); 8)多个 SASL“超级用户”(ZOOKEEPER-3959); 9)快速跟踪受限制的请求 (ZOOKEEPER-3683); 10)其他安全指标 (ZOOKEEPER-3978); 11)C 和 Perl 客户端中的 SASL 支持(ZOOKEEPER-1112、ZOOKEEPER-3714); 12)新的 zkSnapshotComparer.sh 工具(ZOOKEEPER-3427); 13)关于如何使用 YCSB 工具对 ZooKeeper 进行基准测试的说明 (ZOOKEEPER-3264)。 来自 3.5 和 3.6 分支的 ZooKeeper 客户端与 3.7 服务器完全兼容。 从 3.6.x 到 3.7.0 的升级可以照常执行,不需要特别的额外升级过程。 ZooKeeper 3.7.0 客户端与 3.5 和 3.6 服务器兼容,只要您不使用不存在这些版本的新 API。 |
| ZooKeeper 3.6.4 | 2022.12.30 | 该版本是 3.6 分支的最后一个错误修复版本。 它修复了 42 个问题,包括 CVE 修复、log4j1 删除(从现在开始使用 reload4j) 和各种其他错误修复(例如快照、SASL 和 C 客户端相关修复)。 |
| ZooKeeper 3.6.3 | 2021.04.13 | 该版本是 3.6 分支的错误修复版本。 它修复了 52 个问题,包括多个 CVE 修复。 |
| ZooKeeper 3.6.2 | 2020.09.09 | 该版本是 3.6 分支的错误修复版本。 这是一个次要版本,它修复了一些关键问题,并带来了一些依赖项升级。 |
| ZooKeeper 3.6.1 | 2020.04.30 | 该版本是 3.6 分支的第二个版本。 这是一个错误修复版本,它修复了与为 ZooKeeper 3.5 构建的应用程序的一些兼容性问题。从 3.5.7 到 3.6.1 的升级可以照常执行,不需要特别的额外升级过程。ZooKeeper 3.6.1 客户端与 3.5 服务器兼容,只要您不使用 3.5 中不存在的新 API。 |
| ZooKeeper 3.6.0 | 2020.03.04 | 该版本是 3.6 分支的第一个版本。 它带来了许多新功能,并围绕性能和安全性进行了改进。它还在客户端引入了新的 API。 来自 3.4 和 3.5 分支的 ZooKeeper 客户端与 3.6 服务器完全兼容。从 3.5.7 到 3.6.0 的升级可以照常执行,不需要特别的额外升级过程。ZooKeeper 3.6.0 客户端与 3.5 服务器兼容,只要您不使用 3.5 中不存在的新 API。 |
| ZooKeeper 3.5.10 | 2022.06.04 | 该版本是 3.5 分支的最后一个错误修复版本,因为 3.5 是自 2022.6.01起的 EoL。 它修复了 4 个问题,包括 CVE 修复、log4j1 删除(从现在开始使用 reload4j ) 和各种其他错误修复(线程泄漏、数据损坏、快照和 SASL 相关修复)。 |
| ZooKeeper 3.5.9 | 2021.01.15 | 该版本是 3.5 分支的错误修复版本。 它修复了 25 个问题,包括多个 CVE 修复。 |
| ZooKeeper 3.5.8 | 2020.05.11 | 该版本是 3.5 分支的错误修复版本。 它修复了 24 个问题,包括第三方 CVE 修复、几个与领导者选举相关的修复以及与针对早期 3.5 客户端库构建的应用程序的兼容性问题(通过恢复一些非公共 API)。 |
| ZooKeeper 3.5.7 | 2020.02.14 | 该版本是 3.5 分支的错误修复版本。 它修复了 25 个问题,包括第三方 CVE 修复、潜在的数据丢失和潜在的脑裂(如果存在一些罕见情况)。 |
| ZooKeeper 3.5.6 | 2019.10.19 | 该版本是 3.5 分支的错误修复版本。 它修复了 29 个问题,包括 CVE 修复、主机名解析问题和可能的内存泄漏。 文档找不到啦! |
| ZooKeeper 3.5.5 | 2019.05.20 | 该版本是3.5 分支的第一个稳定版本。建议的最低 JDK 版本现在为 1.8。此版本被认为是 3.4 稳定分支的后续版本,建议用于生产。从此版本开始,apache-zookeeper-X.Y.Z.tar.gz 是标准的纯源代码版本, apache-zookeeper-X.Y.Z-bin.tar.gz 是包含二进制文件的方便压缩包 它包含 950 个提交,解决了 744 个问题,修复了 470 个错误,并包括以下新功能: 1)动态重配置 2)本地会话 3)新节点类型:容器、TTL 4)对原子广播协议的 SSL 支持 5)能够删除观察程序 6)多线程提交处理器 7)升级到 Netty 4.1 8)Maven 构建 |
| ZooKeeper 3.5.4-beta | 2018.05.17 | 3.5.4-beta 是计划中的 3.5 版本系列中的第二个测试版,之后将发布稳定的 3.5 版本。它包括 113 个错误修复和改进。版本 3.5.3 添加了新功能 ZOOKEEPER-2169“启用使用 TTL 创建节点”。在实施 TTL 节点时存在重大疏忽。每个服务器的会话 ID 生成器都以高字节中配置的服务器 ID 为种子。TTL 节点在临时所有者中使用时使用最高位来表示 TTL 节点。这意味着创建临时节点的服务器 ID > 127 将始终将这些节点视为 TTL 节点(TTL 本质上是一个随机数)。ZOOKEEPER-2901 修复了该问题。默认情况下,TTL 处于禁用状态,现在必须在 zoo .cfg 中启用。启用 TTL 节点后,最大服务器 ID 将从 255 更改为 254。 |
| ZooKeeper 3.5.3-beta | 2017.04.17 | 3.5.3-beta 是计划中的 3.5 版本线中的第一个测试版,之后将发布稳定的 3.5 版本。它包括 76 个错误修复和改进。此版本包括有关动态重新配置 API 的重要安全修复、对测试基础架构的改进以及 TTL 节点等新功能。 |
| ZooKeeper 3.5.2-alpha | 2016.07.20 | 这是一个 alpha 版本,包含许多错误修复和改进。 |
| ZooKeeper 3.5.1-alpha | 2015.08.31 | 这是一个 alpha 版本,包含许多错误修复和改进。它还引入了一些新功能,包括容器 znodes 和对客户端-服务器通信的 SSL 支持。 |
| ZooKeeper 3.5.0-alpha | 2014.08.06 | 此版本是 alpha 版本,包含许多改进、新功能、错误修复和优化。 |
| ZooKeeper 3.4.14 | 2019.04.02 | 这是一个错误修复版本。它修复了 8 个问题,主要是构建/单元测试问题、由 OWASP、NPE 标记的依赖项更新和名称解析问题。其中,它还支持实验性的 Maven 构建和基于 Markdown 的文档生成。 |
| ZooKeeper 3.4.13 | 2018.07.15 | 这是一个错误修复版本。它修复了 17 个问题,包括 ZOOKEEPER-2959 等问题,这些问题在使用观察器时可能导致数据丢失,以及 ZOOKEEPER-2184 阻止 ZooKeeper Java 客户端在动态 IP(容器/云)环境中工作 |
| ZooKeeper 3.4.12 | 2018.05.01 | 此版本修复了 22 个问题,包括在3.4.11中影响 dataDir 和 dataLogDir 的问题 |
| ZooKeeper 3.4.11 | 2017.11.09 | 此版本修复了 53 个问题,包括对 Java 9 的支持和其他关键错误修复。警告:ZOOKEEPER-2960 最近在 3.4.11 中被确定为回归,影响了单独的 dataDir 和 dataLogDir 配置参数的规范(与默认值相比,两者都是单个目录)。它将在 3.4.12 中得到解决。 |
| ZooKeeper 3.4.10 | 2017.03.30 | 此版本修复了 43 个问题,包括通过 SASL 进行安全功能 QuorumPeer 相互身份验证和其他关键错误。 |
| ZooKeeper 3.4.9 | 2016.09.03 | 此版本修复了许多关键错误和改进。 |
| ZooKeeper 3.4.8 | 2016.02.20 | 此版本修复了 9 个问题,最明显的是关闭 ZooKeeper 时的死锁。 |
| ZooKeeper 3.4.6 | 2014.03.10 | 该版本修复了一个关键错误,该错误可能会阻止服务器加入已建立的集合 |
| ZooKeeper 3.4.5 | 2012.11.18 | 该版本修复了可能导致客户端连接问题的关键 bug。 |
| ZooKeeper 3.4.4 | 2012.09.23 | 该版本修复了一个可能导致数据不一致的关键错误。 |
| ZooKeeper 3.4.3 | 2012.02.13 | 此版本修复 3.4.2 中的关键错误。我们现在正在将此版本升级到测试版,因为对 3.4 分支进行了相当多的错误修复,并且 3.4 版本已经发布了一段时间。 |
| ZooKeeper 3.4.2 | 2011.12.29 | 此版本修复了 3.4.1 中的一个严重缺陷。 请注意,这是一个 alpha 版本,我们不建议将其用于生产。请使用稳定版本行 3.3.* 用于生产用途。 |
| ZooKeeper 3.4.1 | 2011.12.16 | 此版本修复了 3.4.0 中数据丢失的关键错误 |
| ZooKeeper 3.4.0 | 2011.11.22 | 由于数据丢失问题,此版本已从下载页面中删除。请不要使用,版本 3.4.1 现已推出。 |
| ZooKeeper 3.3.6 | 2012.08.02 | 该版本修复了可能导致数据丢失的关键错误 |
| ZooKeeper 3.3.5 | 2012.03.20 | 该版本修复了可能导致数据损坏的关键错误 |
| ZooKeeper 3.3.4 | 2011.11.26 | 该版本修复了许多可能导致数据损坏的关键错误 |
| ZooKeeper 3.3.3 | 2011.02.27 | 该版本修复了可能导致数据损坏的两个关键错误。它还解决了其他 12 个问题 |
| ZooKeeper 3.3.2 | 2010.11.11 | 此版本包含许多bug修复 |
| ZooKeeper 3.3.1 | 2010.05.17 | 文档找不到啦! |
| ZooKeeper 3.3.0 | 2010.03.25 | 文档找不到啦! |
| ZooKeeper 3.2.2 | 2009.12.14 | 此版本包含许多bug修复 |
| ZooKeeper 3.2.1 | 2009.09.04 | 文档找不到啦! |
| ZooKeeper 3.2.0 | 2009.07.08 | 文档找不到啦! |
| ZooKeeper 3.1.2 | 2009.12.14 | 此版本包含许多bug修复 |
| ZooKeeper 3.1.1 | 2009.03.27 | 文档找不到啦! |
| ZooKeeper 3.1.0 | 2009.02.13 | 文档找不到啦! |
| ZooKeeper 3.0.1 | 2008.12.04 | 文档找不到啦! |
| ZooKeeper 3.0.0 | 2008.10.27 | 文档找不到啦! |
四、环境搭建
在真实生产环境中一般都是部署在Linux,因此此处仅记录Linux环境如何搭建。
1、环境要求
1)支持的平台
ZooKeeper 由多个组件组成。某些组件受到广泛支持,而其他组件仅在较小的平台上受支持。
- Client 是 Java 客户端库,应用程序使用它来连接到 ZooKeeper 集合。
- Server 是在 ZooKeeper 集合节点上运行的 Java 服务器。
- Native Client 是用 C 语言实现的客户端,类似于 Java 客户端,应用程序使用它来连接到 ZooKeeper 集合。
- Contrib 是指多个可选的附加组件。
| 操作系统 | Client | Server | Native Client | Contrib |
|---|---|---|---|---|
| GNU/Linux | 开发和生产 | 开发和生产 | 开发和生产 | 开发和生产 |
| Solaris | 开发和生产 | 开发和生产 | 不支持 | 不支持 |
| FreeBSD | 开发和生产 | 开发和生产 | 不支持 | 不支持 |
| Windows | 开发和生产 | 开发和生产 | 不支持 | 不支持 |
| Mac OS X | 仅开发 | 仅开发 | 不支持 | 不支持 |
2)软件环境
JDK1.8+(JDK 8 LTS, JDK 11 LTS, JDK 12 - Java 9 、Java 10 不支持)
3)其它说明
需要部署奇数个zookeeper服务实例,并且至少需要部署3个zookeeper服务器实例。
建议在单独的服务器上部署zookeeper,不和别的服务公用。
在雅虎,ZooKeeper 通常部署在专用的 RHEL 机器上,配备双核处理器、2GB RAM 和 80GB IDE 硬盘。
如果只有两台服务器,则处于以下情况:如果其中一台服务器发生故障,则没有足够的计算机来形成多数仲裁。两台服务器本质上不如一台服务器稳定,因为有两个单点故障。
2、下载安装包
从Apache官网获取最新的稳定版本,获取链接
截止20231207,官网最新稳定版本是Apache ZooKeeper 3.8.3
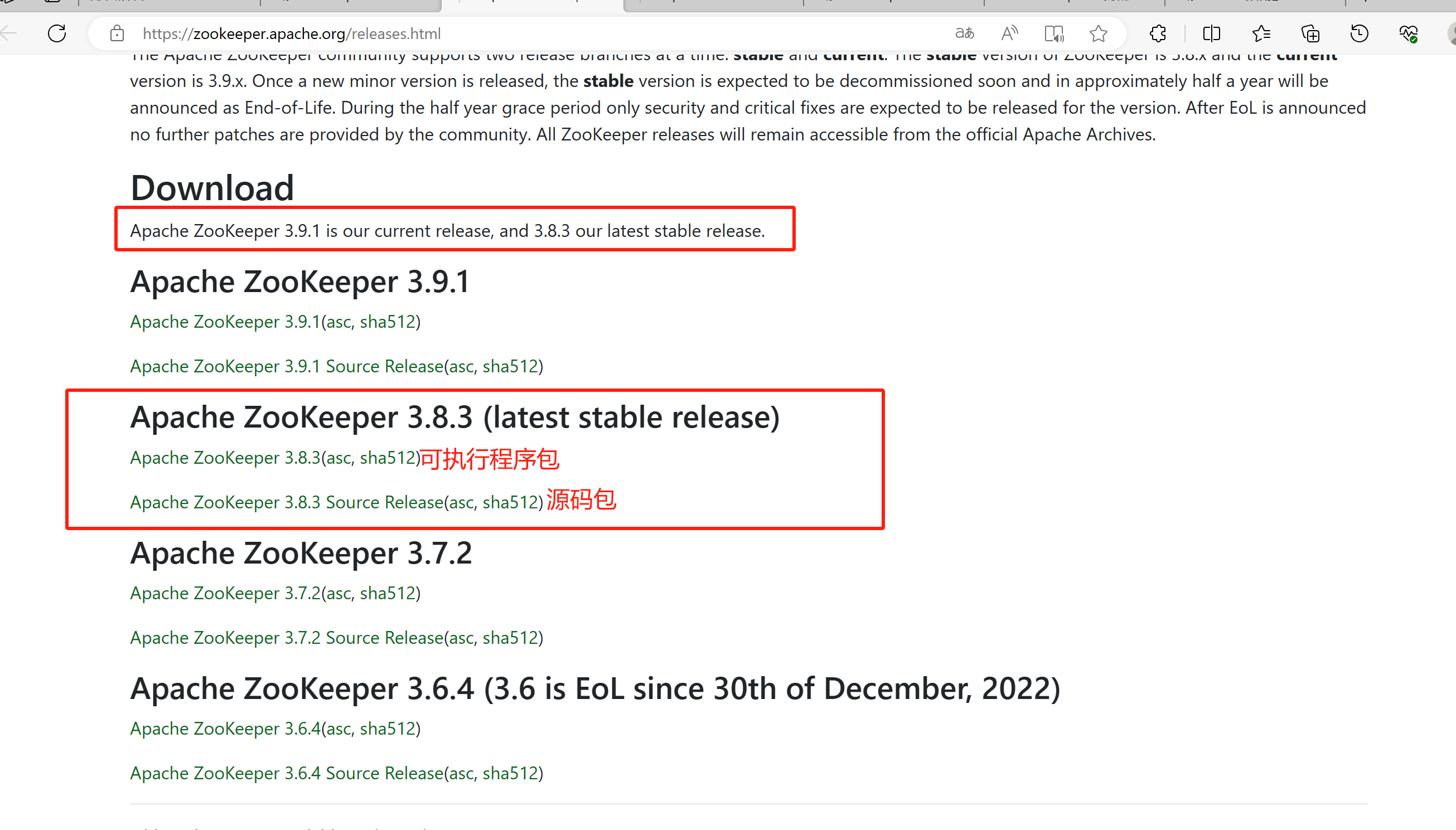
如上图所示,zookeeper提供了源码包和可执行程序包,如果下载源码包,需要在本地进行编译操作,因此我们直接选择编译好的可执行程序包下载到服务器上。
下载好稳定的 ZooKeeper 版本:
[root@XX ~]# ls
apache-zookeeper-3.8.3-bin.tar.gz3、修改配置
下载稳定的 ZooKeeper 版本后,将其解压缩并 cd 到根目录
[root@XX ~]# tar -xvf apache-zookeeper-3.8.3-bin.tar.gz
[root@XX ~]# cd apache-zookeeper-3.8.3-bin
[root@iZbp128dczen7roibd3xciZ apache-zookeeper-3.8.3-bin]# ls
bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.md程序主要目录结构说明
- bin:主要的一些运行命令
- conf:存放配置文件,提供了配置模板文件zoo_sample.cfg
- docs:API文档
- lib:需要依赖的jar包
- LICENSE.txt、NOTICE.txt、README.md、README_packaging.md:Apache开源项目许可证说明、打包等说明
根目录下的conf/目录就是zookeeper的配置文件目录了,cd到conf/目录
[root@XX apache-zookeeper-3.8.3-bin]# cd conf/
[root@XX conf]# ls
configuration.xsl logback.xml zoo_sample.cfg可以看到zookeeper给我们提供了一个配置模板zoo_sample.cfg,大部分情况下我们只需要在当前目录下复制该文件,然后编辑其中的少数几个配置即可
复制生成的目标文件可以称为任何名称,但为了便于讨论,将其称为 conf/zoo.cfg。
# ZooKeeper 使用的基本时间单位(以毫秒为单位)。它用于执行心跳(zk 服务器之间或客户端与服务器之间维持心跳的时间间隔),最小会话超时将是 tickTime 的两倍。
tickTime=2000
#存储内存数据库快照的位置,除非另有说明,否则存储数据库更新的事务日志。
dataDir=/var/lib/zookeeper
# 用于侦听客户端连接的端口
clientPort=2181zk完整的配置说明在后面会进行总结
4、启动服务
返回到程序根目录apache-zookeeper-3.8.3-bin,执行bin/zkServer.sh start
[root@XXX bin]# cd ..
[root@XXX apache-zookeeper-3.8.3-bin]# ls
bin conf docs lib LICENSE.txt logs NOTICE.txt README.md README_packaging.md
[root@XXX apache-zookeeper-3.8.3-bin]# bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/apache-zookeeper-3.8.3-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTEDZooKeeper 使用 logback 记录消息,如果启动正常,将看到发送到控制台的日志消息(默认)和日志文件中的消息。
注意:对于长时间运行的生产系统,必须在外部管理ZooKeeper存储(dataDir 和 logs)。
5、客户端操作
zookeeper在bin目录下自带了一个客户端脚本zkCli.sh,我们使用它来连接到zookeeper服务:
bin/zkCli.sh -server 127.0.0.1:2181连接成功后,应该会看到如下内容:
[root@XXX apache-zookeeper-3.8.3-bin]# bin/zkCli.sh -server 127.0.0.1:2181
Connecting to 127.0.0.1:2181
.....日志略...
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: 127.0.0.1:2181(CONNECTED) 0]连接成功后,可以执行简单的类似文件的操作。
1)列出znode列表
[zk: 127.0.0.1:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 1]2)创建新的znode
创建一个znode,命名为zk_test,写入内容是my_data
[zk: 127.0.0.1:2181(CONNECTED) 1] create /zk_test my_data
Created /zk_test
[zk: 127.0.0.1:2181(CONNECTED) 10] ls -s /zk_test
[]
cZxid = 0x2
ctime = Thu Dec 07 10:27:25 CST 2023
mZxid = 0x2
mtime = Thu Dec 07 10:27:25 CST 2023
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0
[zk: 127.0.0.1:2181(CONNECTED) 11]3)查看znode数据
查看zk_test这个znode的数据
[zk: 127.0.0.1:2181(CONNECTED) 11] get -s /zk_test
my_data
cZxid = 0x2
ctime = Thu Dec 07 10:27:25 CST 2023
mZxid = 0x2
mtime = Thu Dec 07 10:27:25 CST 2023
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0
[zk: 127.0.0.1:2181(CONNECTED) 12]4)修改znode数据
我们可以通过命令来更改与zk_test关联的数据,如下所示:
[zk: 127.0.0.1:2181(CONNECTED) 12] set /zk_test helloworld
[zk: 127.0.0.1:2181(CONNECTED) 14] get -s /zk_test
helloworld
cZxid = 0x2
ctime = Thu Dec 07 10:27:25 CST 2023
mZxid = 0x3
mtime = Thu Dec 07 10:39:25 CST 2023
pZxid = 0x2
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 10
numChildren = 0
[zk: 127.0.0.1:2181(CONNECTED) 15]可以看出修改后,其中的dataVersion从0变成了1。
5)删除znode
删除新增的节点zk_test
[zk: 127.0.0.1:2181(CONNECTED) 15] ls /
[zk_test, zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 16] delete /zk_test
[zk: 127.0.0.1:2181(CONNECTED) 17] ls /
[zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 18]6、集群部署
前面完成了单个zookeeper实例的部署和连接测试,一般我们在生产环境至少部署3台zookeeper服务器组成集群,预防单点故障。下面总结如何部署多个实例。
首先准备拷贝一份zookeeper目录到另外一台服务器上,并修改其中的配置文件zoo.cfg,如下所示:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888可以看出多了一些配置项:
- initLimit -集群中的follower服务器(F)与leader服务器(L)之间 初始连接 时能容忍的最多心跳数(tickTime的数量)。当超过设置倍数的 tickTime 时间,则连接失败。
- syncLimit -集群中的follower服务器(F)与leader服务器(L)之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)。如果 follower 在设置的时间内不能与leader 进行通信,那么此 follower 将被丢弃。
- server.x - 列出组成集群的zk服务器标识,这里的x是一个数字,与myid文件中的id是一致的。右边可以配置两个端口,第一个端口用于F和L之间的数据同步和其它通信,第二个端口用于Leader选举过程中投票通信
在上面配置示例中,initLimit 的超时为 5 个时钟周期,每个时钟周期 2000 毫秒,即 10 秒。总共有三台zk实例,标识分布是zoo1、zoo2、zoo3。
五、基本知识
此处总结zookeeper基础知识,后续也会持续更新补充本小节的内容
1、数据存储模型
在文章开头的简介中,提到过zookeeper的数据模型和分层命名空间,这里详细说明一下相关的概念。
与标准文件系统不同,ZooKeeper 命名空间中的每个节点都可以有与之关联的数据以及子节点。这就像有一个文件系统,允许文件也是一个目录。我们使用官方术语 znode 来表示一个 ZooKeeper的 数据节点。
Znodes 维护一个统计信息结构,其中包括数据更改、ACL 更改和时间戳的版本号,以允许缓存验证和协调更新。每当 znode 的数据发生变化时,版本号就会增加。例如,每当客户端检索数据时,它也会接收数据的版本。存储在命名空间中每个 znode 的数据都是以原子方式读取和写入的。读取获取与 znode 关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表 (ACL),用于限制谁可以执行哪些操作。
ZooKeeper 被设计用于存储协调数据:状态信息、配置、位置信息等,因此每个节点存储的数据通常很小,在字节到千字节的范围内。
znode的属性说明:
ZooKeeper 树中的每个节点都称为 znode。通过bin/zkCli.sh start 连接上zk服务后,执行get -s znode_name,可以获取znode(示例znode是zk_test)的属性信息,如下:
[zk: 127.0.0.1:2181(CONNECTED) 11] get -s /zk_test
my_data
cZxid = 0x2
ctime = Thu Dec 07 10:27:25 CST 2023
mZxid = 0x2
mtime = Thu Dec 07 10:27:25 CST 2023
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0其中:
- my_data: 是该节点本身存储的内容。
- cZxid:该节点创建的事务id。
- ctime:该节点创建时的时间。
- mZxid:该节点被修改的事务id,即每次对znode的修改都会更新mZxid。
- mtime:该节点最新一次更新发生时的时间。
- pZxid:表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID。
- cversion:子节点的版本号。当该节点的子节点有变化时,cversion 的值就会增加1。
- dataVersion:数据版本号,数据每次修改该版本号加1。
- aclVersion:权限版本号,权限每次修改该版本号加1。
- ephemeralOwner:如果该节点为临时节点, ephemeralOwner值表示与该节点绑定的session id. 如果不是, ephemeralOwner值为0x0。
- dataLength:该节点的数据长度。
- numChildren:该节点拥有子节点的数量。
Zookeeper里面的版本号和我们理解的版本号不同,它表示的是对数据节点的内容、子节点列表或者ACL信息的修改次数。节点创建时dataversion、aclversion,cversion都为0,每次修改响应内容其对应的版本号加1。
Zookeeper中的版本号其实就是乐观锁的一种思想。两个API操作可以有条件地执行:setData和delete。这两个调用以版本号作为转入参数,只有当转入参数的版本号与服务器上的版本号一致时调用才会成功。当多个Zookeeper客户端对同一个znode进行操作时,版本的作用就会显得尤为重要。

如上图所示,客户端C1对znode/config写入了一些配置信息,如果另一个客户端C2同时更新了这个znode,此时C1的版本过期,C1的setData一定不会成功。使用版本机制避免了数据写入混乱情况。
创建znode时的注意事项:
- 空字符 (\u0000) 不能是znode路径名的一部分。(这会导致 C 绑定出现问题)
- 不能使用以下字符,因为它们不能很好地显示:\u0001 - \u001F 和 \u007F\u009F.
- 不允许使用以下字符:\ud800 - uF8FF、\uFFF0 - uFFFF。
- “.” 字符可以用作另一个名称的一部分,但 “.” 和 “..” 不能单独用于指示路径上的节点,因为 ZooKeeper 不使用相对路径。以下内容无效:“/a/b/./c”或“/a/b/../c”。
- “zookeeper”是zk服务保留使用的znode,不允许我们自行创建。
官方文档中提到,zookeeper的数据存储节点类型分为了持久节点、临时节点、容器节点、TTL 节点。
1)持久节点
持久节点是zookeeper中默认的一种节点类型,也是用的最多的节点类型
2)临时节点
ZooKeeper 也有临时节点的概念。只要创建 znode 的会话处于活动状态,这些 znode 就存在。会话结束时,znode 将被删除。
3)容器节点
在3.5.3版本中,zookeeper增加了容器 znode 的概念。容器 znode 是特殊用途的 znode,可用于 leader、lock 等场景。只要在调用 create 方法时,指定 CreateMode 为 CONTAINER 即可创建 容器 znode类型, 容器 znode的表现形式和持久节点是一样的,但是区别是 ZK 服务端启动后,会有一个单独的线程去扫描所有的容器znode,当发现 容器znode的子节点数量为 0 时,会自动删除该节点,除此之外和 持久 节点没有区别。
4)TTL节点
TTL 是 time to live 的缩写,指带有存活时间的节点,如果 znode 未在 TTL时间范围内 有修改并且没有子节点,则它将在TTL时间到达后被删除。
创建 PERSISTENT 或PERSISTENT_SEQUENTIAL znode 时,可以选择为 znode 设置 TTL(以毫秒为单位)。
#zoo.cfg配置文件
extendedTypesEnabled=true如果尝试在未设置正确 System 属性的情况下创建 TTL 节点,则服务器将引发 KeeperException.UnimplementedException。
5)数据访问
存储在命名空间中每个 znode 的数据都是以原子方式读取和写入的。读取获取与 znode 关联的所有数据,写入替换所有数据。每个节点都有一个访问控制列表 (ACL),用于限制谁可以执行哪些操作。
要特别注意的是,ZooKeeper 并非设计为通用数据库或支持大型对象存储。它设计的初衷是管理协调分布式系统中的协调数据。各种协调数据的一个共同属性是它们相对较小:以千字节为单位。ZooKeeper 客户端和服务器实现具有健全性检查,应确保 znode 存储的数据少于 1M,而且要尽量远低于1M。对相对较大的数据进行操作将导致其他操作可能会被阻塞导致延迟较高,因为通过网络移动到存储介质上需要额外的时间。
如果需要存储大型数据,通常建议是将其存储在大容量存储系统(如 NFS 或 HDFS)上,并在 ZooKeeper 中仅存储指向存储位置的指针。
6)数据目录自动创建
ZooKeeper 将其数据存储在数据目录中,将其事务日志存储在事务日志目录中。默认情况下,这两个目录是相同的。服务器可以(并且应该)配置为将事务日志文件存储在与数据文件不同的目录中。当事务日志驻留在专用日志设备上时,吞吐量会增加,延迟会减少。
数据目录是通过配置文件中的参数dataDir来指定的文件路径。在3.5 中的新功能: ZooKeeper 服务器的默认行为是在启动时自动创建数据目录(在配置文件中指定),如果该目录尚不存在。在某些情况下,这可能会很危险。举个例子,对正在运行的服务器进行配置更改,其中 dataDir 参数被意外更改。当 ZooKeeper 服务器重新启动时,它将创建这个不存在的目录并开始服务 - 使用一个空的 znode 命名空间。这种情况可能会导致有效的“裂脑”情况(即,新的无效目录和原始有效数据存储中的数据)。因此,最好有一个选项来关闭此自动创建行为。 虽然zookeeper并没有在配置文件中提供选项来支持,但是提供了另外一种方式。
在运行时 zkServer.sh 可以通过将环境变量 ZOO_DATADIR_AUTOCREATE_DISABLE 设置为 1 来禁用自动创建。当直接从类文件运行 ZooKeeper 服务器时,这可以通过在 java 命令行上设置 zookeeper.datadir.autocreate=false 来实现,即 -Dzookeeper.datadir.autocreate=false。当禁用此功能时,如果 ZooKeeper 服务器确定所需的目录不存在,在启动时它将生成错误并拒绝启动。
新版本还提供了 zkServer-initialize.sh 来支持此新功能。如果禁用了自动创建,则用户需要先安装 ZooKeeper,然后创建数据目录(可能还有 事务日志txnlog 目录),然后启动服务器。运行 zkServer-initialize.sh 将创建所需的目录,并选择性地设置 myid 文件(可选的命令行参数)。即使未使用自动创建功能本身,也可以使用此脚本,并且可能对用户有用,因为这(设置,包括创建 myid 文件)过去一直是用户的问题。请注意,此脚本确保数据目录仅存在,它不会创建配置文件,而是需要配置文件可用才能执行。
2、数据文件管理
ZooKeeper 将其数据存储在数据目录中,将其事务日志存储在事务日志目录中。默认情况下,这两个目录是相同的。服务器可以(并且应该)配置为将事务日志文件存储在与数据文件不同的目录中。当事务日志驻留在专用日志设备上时,吞吐量会增加,延迟会减少。
需要注意的是,存储在这些文件中的数据未加密。在ZooKeeper中存储敏感数据的情况下,需要采取必要的措施来防止未经授权的访问。此类措施是 ZooKeeper 外部的(例如,控制对文件的访问),并且取决于部署它的各个设置。
1)数据目录
此目录中有两个或三个文件:
myid - 包含一个以人类可读的 ASCII 文本表示服务器 ID 的整数。
每个 ZooKeeper 服务器都有一个唯一的 ID。此 ID 用于两个位置:myid 文件和配置文件。myid 文件标识与给定数据目录对应的服务器。配置文件列出了由其服务器 ID 标识的每个服务器的联系信息。当 ZooKeeper 服务器实例启动时,它会从 myid 文件中读取其 id,然后使用该 id 从配置文件中读取,查找它应该侦听的端口。
initialize - 存在表示预计缺少数据树。创建数据树后进行清理。
snapshot. - 保存数据树的模糊快照。
存储在数据目录中的快照文件是模糊快照,因为在 ZooKeeper 服务器拍摄快照期间,数据树正在发生更新。快照文件名的后缀是快照开始时最后一个提交事务的 zxid,即 ZooKeeper 事务 ID。因此,快照包括快照过程中发生的数据树更新的子集。因此,快照可能与实际存在的任何数据树不对应,因此我们将其称为模糊快照。尽管如此,ZooKeeper 仍然可以使用此快照进行恢复,因为它利用了其更新的幂等性。通过针对模糊快照重放事务日志,ZooKeeper 在日志末尾获取系统状态。
2)事务日志目录
日志目录包含 ZooKeeper 事务日志。在进行任何更新之前,ZooKeeper 确保将表示更新的事务写入非易失性存储器。当写入当前日志文件的事务数达到(可变)阈值时,将启动新的日志文件。阈值是使用影响快照频率的相同参数计算的(请参阅上面的 snapCount 和 snapSizeLimitInKb)。日志文件的后缀是写入该日志的第一个 zxid。
3)文件管理
快照和日志文件的格式在独立的 ZooKeeper 服务器和复制的 ZooKeeper 服务器的不同配置之间不会改变。因此,您可以将这些文件从正在运行的复制 ZooKeeper 服务器拉取到具有独立 ZooKeeper 服务器的开发计算机,以便进行故障排除。
使用较旧的日志和快照文件,我们可以查看 ZooKeeper 服务器的先前状态,甚至可以恢复该状态。
ZooKeeper 服务器创建快照和日志文件,但从不删除它们。数据和日志文件的保留策略是在 ZooKeeper 服务器外部实现的。服务器本身只需要最新的完整模糊快照、它后面的所有日志文件以及它前面的最后一个日志文件。
3、watch机制
ZooKeeper: Because Coordinating Distributed Systems is a Zoo (apache.org)
1)底层原理
ZooKeeper官方 对watch的定义:watch事件是一次性触发,发送到设置watch的客户端,当设置watch的数据发生变化时发生。
客户端可以在 znode 上设置watch监听器,接受监听事件。监听事件是一次性的,发送到设置监听器的客户端后,会将对应监听器删除。
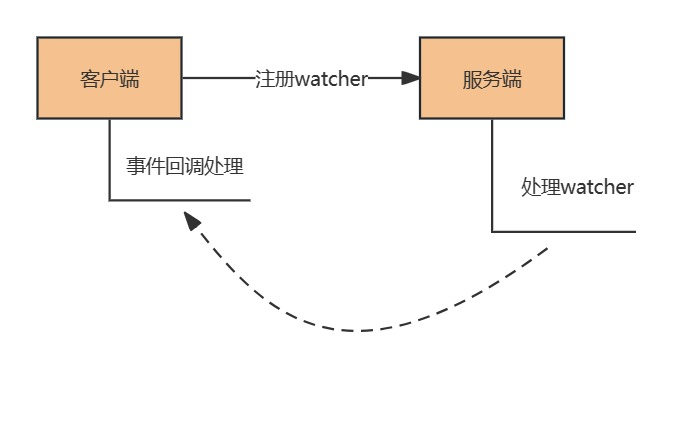
zookeeper的watch设计思想很像设计模式中的”观察者模式“,一个znode节点可能会被多个客户端监控,当对应事件被触发时,会通知这些客户端。
ZooKeeper 中 Watch 机制的实现的方式是通过客服端和服务端分别创建有观察者的信息列表。客户端调用 getData、exist 等接口时,首先将对应的 Watch 事件放到本地的 ZKWatchManager 中进行管理。服务端在接收到客户端的请求后根据请求类型判断是否含有 Watch 事件,并将对应事件放到 WatchManager 中进行管理。
在事件触发的时候服务端通过节点的路径信息查询相应的 Watch 事件通知给客户端,客户端在接收到通知后,首先查询本地的 ZKWatchManager 获得对应的 Watch 信息处理回调操作。
这种设计不但实现了一个分布式环境下的观察者模式,而且通过将客户端和服务端各自处理 Watch 事件所需要的额外信息分别保存在两端,减少彼此通信的内容,提升了服务的处理性能。
2)何时触发
对 znode 的更改会触发监听器。当znode有变更时,ZooKeeper 会向客户端发送本地通知,最多发送一次后watch监听器就会自动失效。
ZooKeeper 中的所有读取操作 - getData()、getChildren() 和 exists() - 都可以被监听。
例如:如果客户端执行 getData(“/znode1”, true),并且稍后更改或删除了 /znode1 的数据,则客户端将获得 /znode1 的watch监听事件(异步获得)。如果 /znode1 再次更改,则不会发送watch事件,除非客户端重新设置一次新的监听器。
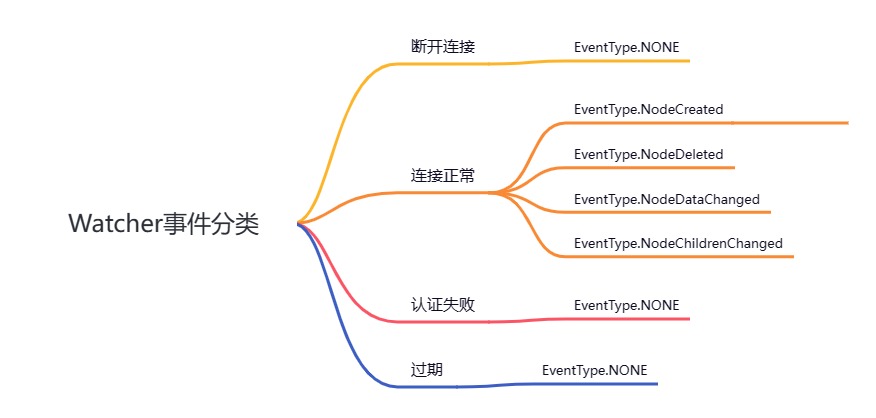
下面图中列出了客户端在不同会话状态下,相应的在服务器节点所能支持的事件类型。
例如在客户端连接服务端的时候,可以对数据节点的创建、删除、数据变更、子节点的更新等操作进行监控。
3)其它说明
watch在客户端连接到的 ZooKeeper 服务器上本地维护,Watcher 将作为整个 ZooKeeper 会话期间的上下文 ,一直被保存在客户端 ZKWatchManager 的 defaultWatcher 中 。
当客户端与服务器断开连接时,不会收到watch事件。当客户端重新连接时,将重新注册并在需要时触发任何以前注册的watch事件。
有一种情况可能会错过监听事件:如果在断开连接时创建并删除了 znode,则将错过尚未创建的 znode 存在的watch事件。
3.6.0 中的新功能: 客户端可以在 znode 上设置永久的递归监听事件,这些监听事件在触发时不会被删除,并且会以递归方式触发已注册的 znode 以及任何子 znode 上的更改。
4)应用案例
在分布式应用开发的过程中会用到各种各样的配置信息,如应用本身业务配置、第三方接口调用地址、数据库信息等等,我们可以将这些配置集中管理,然后利用ZooKeeper 的watcher机制解决分布式应用中的配置实时通知功能。
我们可以在zookeeper创建一个znode节点,然后把上面的信息存储于该节点中。
然后服务器集群客户端对该节点添加 Watch 事件监控,当集群中的服务启动时,会读取该节点数据获取数据配置信息。而当该节点数据发生变化时,ZooKeeper 服务器会发送 Watch 事件给各个客户端,集群中的客户端在接收到该通知后,重新读取最新的配置信息。
目前市面上已经有很多优秀的开源分布式配置集中管理系统,比如Apollo、Nacos等,真实业务场景还是建议直接采用这些优秀的开源轮子,而不是重新开发配置管理系统了,毕竟咱不要重复造轮子,除非你能比他们更优秀!
4、会话机制
若要创建客户端会话,应用程序代码必须提供一个zookeeper连接配置字符串,其中包含以逗号分隔的主机:端口对列表,每个对应于 ZooKeeper 服务器。字符串格式示例如下:
"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002"ZooKeeper 客户端库将选择连接字符串中的任意一台服务器地址并尝试连接到它。如果此连接失败,或者客户端由于任何原因与服务器断开连接,则客户端将自动尝试列表中的下一个服务器,直到(重新)建立连接。
ZK Server在配置集群时,会在配置文件指定明确的服务器IP和端口,然后启动。如果中途某台挂了,那么只要在一定数量范围之内不影响,但是如果想要增加几台,需要在每台ZK Server上的配置文件上都加入新增加的IP和端口,最重要一点就是要重启所有的ZK Server才能使其生效。
下图显示了 ZooKeeper 客户端与服务器在连接过程中可能的状态转换:
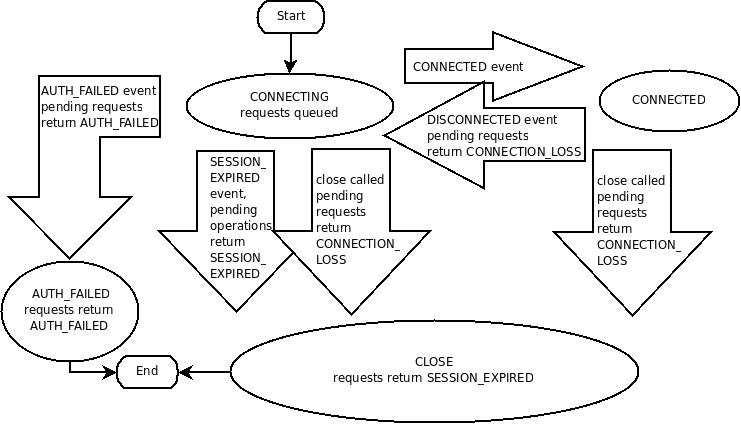
ZooKeeper 客户端通过使用的编程语言创建服务的句柄来建立与 ZooKeeper 服务的会话。创建后,句柄以 CONNECTING 状态启动,客户端库尝试连接到组成 ZooKeeper 服务集群的其中一个实例,此时它将切换到 CONNECTED 状态。在正常操作期间,客户端句柄将处于这两种状态之一。如果发生不可恢复的错误(如会话过期或身份验证失败),或者应用程序显式关闭句柄,则句柄将移至 CLOSED 状态。
当客户端获取 到ZooKeeper 服务的句柄时,ZooKeeper 会创建一个 代表ZooKeeper 会话的64 位数字,并将其分配给客户端。如果客户端连接到其他 ZooKeeper 服务器,它将发送会话 ID 作为连接握手的一部分。服务器会为该会话 ID 创建一个密码,任何 ZooKeeper 服务器都可以验证该密码。当客户端建立会话时,密码将随会话 ID 一起发送到客户端。每当客户端与新服务器重新建立会话时,客户端都会将此密码与会话 ID 一起发送。
异常说明
在3.2.0版本中增加了SessionMovedException。发生此异常的原因是,已在其他服务器上重新建立的会话的连接上收到了请求。此错误的正常原因是客户端向服务器发送请求,但网络数据包延迟,因此客户端超时并连接到新服务器。当延迟的数据包到达第一台服务器时,旧服务器检测到会话已移动,并关闭客户端连接。
5、分组和权重
Zookeeper的集群有一个法则,整个集群的数量要过半存活,集群就是稳定的。在这法则之外,官方文档中还提供了分组(Group)和权重(Weight)的配置。Zookeeper的Group配置的意思就是对整个大的zk集群进行分组。
例如,我们有1、2、3、4、5、6、7总共7个节点。我们做如下配置:
group.1=1:2:3
group.2=4:5:6
group.2=7将7台机器分为三个组,这时,只要三个组中的两个是稳定的,整个集群的状态就是稳定的。即有2n+1个组,只要有n+1个组是稳定状态,整个集群就是稳定的。也就是过半原则。
Zookeeper的Weight配置要和Group配置一起使用。官方文档中介绍Weight时提到此值影响集群节点Leader的选取,经过实际测试和翻阅zk的投票源码,Weight等于0的节点不参与投票,没有被选举权,而不影响投票的权重。摘抄源码片段如下:
protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch,long curId, long curZxid, long curEpoch){
if (self.getQuorumVerifier().getWeight(newId) == 0){
return false;
}
return ((newEpoch > curEpoch) ||
(newEpoch == curEpoch && newZxid > curZxid) ||
(newZxid == curZxid && newId > curId));
}Weight可以调节一个组内单个节点的权重,默认每个节点的权重是1(如果配置是0不参与leader的选举)。每个组有一个法定数的概念,法定人数等于组内所有节点的权重之和.此时判断一个组是否稳定,是要判断存活的节点权重之和是否大于该组法定数的权重.
接上面的例子,我们做如下配置:
weight.1=1
weight.2=1
weight.3=1
weight.4=1
weight.5=1
weight.6=1
weight.7=1此时Group1的法定数是:3+1+1=5,只要节点权重之和过半该组就是稳定的。也就是说,该组中,节点1(权重是3)只要存活,该组就是稳定的. 经过以上配置,停掉节点2,3,4,5,6整个集群仍然是稳定的. 此时Group1和Group3是稳定状态.
6、配置详解
ZooKeeper: Because Coordinating Distributed Systems is a Zoo (apache.org)
1)基本配置
| 配置项 | 含义 | 默认值 |
|---|---|---|
| tickTime | 客户端与服务器或者服务器与服务器之间维持心跳的时间间隔,单位是毫秒 | 2000 |
| dataDir | 存储内存中数据库快照的位置,也称为snapshot快照文件目录,用来存放myid信息跟一些版本日志,还有服务器唯一的ID信息等。 | /tmp/zookeeper |
| clientPort | 客户端连接的端口号,客户端连接zookeeper服务器的端口,zookeeper会监听这个端口,接收客户端的请求访问。 | 2181 |
| secureClientPort | 客户端SSL连接的端口。而clientPort是明文连接的端口,指定两者将启用混合模式,而省略其中任何一个都将禁用该模式。需要开启SSL认证方式还需要开启如下两个配置:zookeeper.serverCnxnFactory、zookeeper.clientCnxnSocket | |
2)高级配置
| 配置项 | 含义 | 默认值 |
|---|---|---|
| dataLogDir | 存放事务日志的文件夹。未指定时日志文件存放在dataDir目录中,一般建议创建dataDir和dataLogDir,将数据文件和日志文件区分存放在不同的位置,这有助于避免日志记录和快照之间的竞争。拥有专用日志设备对吞吐量和稳定的延迟有很大影响。强烈建议事务日志存放于专用日志设备 | |
| globalOutstandingLimit | 当客户端提交请求的速度比 ZooKeeper 处理请求的速度快,尤其是在客户端很多的情况下。为了防止 ZooKeeper 因请求积压排队而耗尽内存,ZooKeeper 将限制客户端访问使整个排队集合中不超过 globalOutstandingLimit个 未完成的请求。 对应Java 系统属性:zookeeper.globalOutstandingLimit | 默认限制为 1,000,例如有 3 个成员,每个成员将有 1000 / 2 = 500 个单独的限制。 |
| preAllocSize | 预分配的事务日志文件块大小,ZooKeeper 以 preAllocSize 千字节的块为单位分配事务日志文件中的空间 对应Java系统属性:zookeeper.preAllocSize | 默认块大小为 64M |
| snapCount | ZooKeeper 使用快照和事务日志记录其事务数据。ZK 使用事务日志和快照来记录事务(考虑 提前写日志 write-ahead log). snapCount 决定了多少个事务日志之后会开始产生快照. 为了防止所有的成员同时生成快照, 每个 ZK服务器会产生一个随机数处于 [snapCount/2+1, snapCount] 之间, 在达到这个随机数之后就会产生快照。 对应Java系统属性:zookeeper.snapCount | 100000 |
| commitLogCount | ZK会在内存中维护一部分已提交的请求列表以供服务器间同步最近的请求的使用. 在快照很大的时候(> 100,000), 能提高同步的性能。 对应Java系统属性:zookeeper.commitLogCount | 500 |
| snapSizeLimitInKb | 和 snapCount做作用类似 , 但是这个使用的是文件大小来进行限制。在生成快照(以及滚转事务日志)之前,事务日志中记录的事务集允许的总字节大小由snapSizeLimitInKb确定。 对应Java系统属性:zookeeper.snapSizeLimitInKb | 默认是 4,194,304 (4GB), 负数表示不开启这个功能. |
| txnLogSizeLimitInKb | 可以使用 txnLogSizeLimitInKb 更直接地控制 Zookeeper 事务日志文件。使用事务日志完成同步时,较大的 txn 日志可能会导致关注者同步速度变慢。这是因为领导者必须扫描磁盘上的相应日志文件,以查找要从中启动同步的事务。默认情况下,此功能处于关闭状态,snapCount 和 snapSizeLimitInKb 是唯一限制事务日志大小的值。启用后,Zookeeper 将在达到任何限制时滚动日志。请注意,实际日志大小可能会超过此值,因为序列化事务的大小。另一方面,如果此值设置得太接近(或小于)preAllocSize,则可能导致 Zookeeper 为每个事务滚动日志。虽然这不是正确性问题,但这可能会导致性能严重下降。为了避免这种情况并充分利用此功能,建议将值设置为 N * preAllocSize,其中 N >= 2。 对应Java系统属性:zookeeper.txnLogSizeLimitInKb | 默认情况下,此功能处于关闭状态 |
| maxCnxns | 限制每个zk服务器并发的连接总数(每个服务器的每个客户端端口). 用来防止特定类型的 DOS 攻击。 因为 serverCnxnFactory 和 secureServerCnxnFactory 是分开算的,所以最多的连接数是 2 *maxCnxns。 对应Java系统属性:zookeeper.maxCnxns | 默认是 0, 表示没有限制.。 |
| maxClientCnxns | 在 socket 层面限制一个客户端(根据ip)允许连接zk集群中某个服务器的最大连接数 限制范围仅仅是单台客户机对单台服务器之间的链接数限制,并不能控制集群中所有客户端的连接数总和。 | 默认60. 设置成0 表示没有限制 |
| clientPortAddress | 3.3.0新增,用于侦听客户端连接的地址(IPv4、IPv6 或主机名), 默认监听使用 clientPort 的所有连接 | |
| minSessionTimeout | 3.3.0新增,服务器允许客户端协商的最小会话超时(以毫秒为单位)。 | 默认值为 tickTime 的 2 倍。 |
| maxSessionTimeout | 3.3.0新增,服务器允许客户端协商的最大会话超时(以毫秒为单位)。 | 默认值为 tickTime 的 20 倍。 |
| fsync.warningthresholdms | 3.3.4新增,事务日志执行 fsync 的时候超过了这个毫秒数就会打印警告信息。 对应Java系统属性:zookeeper.fsync.warningthresholdms | 默认 1000 |
| maxResponseCacheSize | 确定存储最近读取记录的序列化形式的缓存的大小, 可以使用 response_packet_cache_hits 和 response_packet_cache_misses 指标来调整这个值。 对应Java系统属性:zookeeper.maxResponseCacheSize | 默认是 400, 负数或者 0 表示不启用。 |
| maxGetChildrenResponseCacheSize | 3.6.0新增,与 maxResponseCacheSize 类似,但适用于获取子请求。可以使用指标 response_packet_get_children_cache_hits和 response_packet_get_children_cache_misses来调整这个值。 对应Java系统属性:zookeeper.maxGetChildrenResponseCacheSize | 默认是 400, 负数或者 0 表示不启用。 |
| autopurge.snapRetainCount | 3.4.0新增,ZooKeeper 自动清除功能分别在 dataDir 和 dataLogDir中保留 最新快照和相应的事务日志的个数,并删除其余部分。 | 默认值为 3。最小值为 3。 |
| autopurge.purgeInterval | 3.4.0新增,触发自动清除日志任务的间隔。 | 默认是0表示不开启(以小时为单位) |
| syncEnabled | 3.4.6, 3.5.0新增,是否允许让观察者和其他参与者一样把事务日志写到磁盘, 减少观察者重启恢复的时间。 对应Java系统属性:zookeeper.observer.syncEnabled | 默认是true , 设置为 false 关闭。 |
| extendedTypesEnabled | 3.5.4,3.6.0新增,定义以启用扩展功能,例如创建 TTL 节点]。默认情况下,它们处于禁用状态。重要说明:启用后,由于内部限制,服务器 ID 必须小于 255。 仅限Java系统属性:zookeeper.extendedTypesEnabled | |
| emulate353TTLNodes | 3.5.4、3.6.0新增,由于ZOOKEEPER-2901,3.5.4/3.6.0版本中不支持在3.5.3中创建的TTL节点。然而,通过zookeeper.emulate353TTLNodes系统属性提供了解决办法。如果您在ZooKeeper 3.5.3中使用了TTL节点,并且除了zookeeper.extendedTypesEnabled外,还需要将zookeeper.emulate353TTLNodes的兼容性保持为true。注意:由于错误,服务器ID必须为127或更少。此外,最大支持TTL值为1099511627775,小于3.5.3(1152921504606846975)中允许的值。仅限Java系统属性:zookeeper.emulate353TTLNodes | |
| watchManagerName | 3.6.0新增,在ZOOKEEPER-1179添加, 添加了新的观察程序管理器 WatchManagerOptimized,以优化繁重的监视用例中的内存开销。此配置用于定义要使用的观察程序管理器。目前,我们仅支持 WatchManager 和 WatchManagerOptimized。 仅限Java系统属性:zookeeper.watchManagerName | |
| watcherCleanThreadsNum | 3.6.0新增,在 ZOOKEEPER-1179添加, 新的观察者管理器 WatchManagerOptimized 将异步并发地清理下线的观察者,此配置用于决定 WatcherCleaner 中使用了多少线程。线程越多,通常意味着清理吞吐量越大。默认值为 2,即使对于繁重且连续的会话关闭/重新创建案例,也足够好。 仅限Java系统属性:zookeeper.watcherCleanThreadsNum | 2 |
| watcherCleanThreshold | 3.6.0新增,新增于 ZOOKEEPER-1179。新的 watcher 管理器 WatchManagerOptimized 会懒惰地清理死掉的 watcher,清理过程比较繁重,批处理会降低成本,提高性能。此设置用于确定批大小。默认值为 1000,如果没有内存或清理速度问题,我们不需要更改它。 仅限Java系统属性:zookeeper.watcherCleanThreshold | 1000 |
| watcherCleanIntervalInSeconds | 3.6.0新增,新增于 ZOOKEEPER-1179。新的 watcher 管理器 WatchManagerOptimized 会懒惰地清理死掉的 watcher,清理过程比较繁重,批处理会降低成本,提高性能。除了 watcherCleanThreshold 之外,此设置还用于在一定时间后清理死的watcher,即使死的watcher不大于 watcherCleanThreshold,这样我们就不会将死的观察者留在那里太久。 仅限Java系统属性:zookeeper.watcherCleanIntervalInSeconds | 默认设置为 10 分钟,通常不需要更改。 |
| maxInProcessingDeadWatchers | 3.6.0新增,新增于 ZOOKEEPER-1179,控制我们在 WatcherCleaner 中可以有多少积压,当它达到这个数字时,它会减慢向 WatcherCleaner 添加死观察者的速度,这反过来又会减慢添加和关闭观察者的速度,这就可以避免 OOM 问题。 仅限于Java系统属性:zookeeper.maxInProcessingDeadWatchers | 默认情况下没有限制,可以将其设置为 watcherCleanThreshold * 1000 等值。 |
| bitHashCacheSize | 3.6.0新增,新增于ZOOKEEPER-1179。这是用于确定 BitHashSet 实现中的 HashSet 缓存大小的设置 仅限于Java系统属性:zookeeper.bitHashCacheSize | |
| fastleader.minNotificationInterval | 领导者选举中两次连续通知检查之间的时间长度的下限。此间隔决定了对等方等待检查选举票集的时间,并影响选举解决的速度。对于长时间选举,间隔遵循从配置的最小值 (this) 和配置的最大值 (fastleader.maxNotificationInterval) 的退避策略。 Java系统属性:zookeeper.fastleader.minNotificationInterval | |
| fastleader.maxNotificationInterval | 领导者选举中两次连续通知检查之间的时间长度上限。此间隔决定了对等方等待检查选举票集的时间,并影响选举解决的速度。对于长时间选举,间隔遵循从配置的最小值 (fastleader.minNotificationInterval) 和配置的最大值 (this) 开始的回退策略。 Java系统属性:zookeeper.fastleader.maxNotificationInterval | |
| connectionMaxTokens | 3.6.0新增,这是用于优化服务器端连接限制程序的参数之一,服务器端连接限制器是一种基于令牌的速率限制机制,具有可选的概率丢弃。此参数定义 token-bucket 中的最大令牌数。设置为 0 时,将禁用限制。默认值为 0。 Java系统属性:zookeeper.connection_throttle_tokens | 默认值为 0。 |
| connectionTokenFillTime | 3.6.0新增,这是用于优化服务器端连接限制程序的参数之一,服务器端连接限制器是一种基于令牌的速率限制机制,具有可选的概率丢弃。此参数定义使用 connectionTokenFillCount 令牌重新填充令牌存储桶的时间间隔(以毫秒为单位)。 Java系统属性:zookeeper.connection_throttle_fill_time | 默认值为 1。 |
| connectionTokenFillCount | 3.6.0新增,这是用于优化服务器端连接限制程序的参数之一,服务器端连接限制器是一种基于令牌的速率限制机制,具有可选的概率丢弃。此参数定义每 connectionTokenFillTime 毫秒要添加到令牌存储桶的令牌数。 Java系统属性:zookeeper.connection_throttle_fill_count | 默认值为 1。 |
| connectionFreezeTime | 3.6.0新增,这是用于优化服务器端连接限制程序的参数之一,服务器端连接限制器是一种基于令牌的速率限制机制,具有可选的概率丢弃。此参数定义调整丢弃概率时的间隔(以毫秒为单位)。设置为 -1 时,禁用概率删除。 Java系统属性:zookeeper.connection_throttle_freeze_time | 默认值为 -1。 |
| connectionDropIncrease | 3.6.0新增,这是用于优化服务器端连接限制程序的参数之一,服务器端连接限制器是一种基于令牌的速率限制机制,具有可选的概率丢弃。此参数定义增加的丢弃概率。限制器检查每个 connectionFreezeTime 毫秒,如果令牌存储桶为空,则丢弃概率将增加 connectionDropIncrease。 Java系统属性:connection_throttle_drop_increase | 默认值为 0.02。 |
| connectionDropDecrease | 3.6.0新增,这是用于优化服务器端连接限制程序的参数之一,服务器端连接限制器是一种基于令牌的速率限制机制,具有可选的概率丢弃。此参数定义下降概率。限制器检查每个 connectionFreezeTime 毫秒,如果令牌存储桶的令牌数超过阈值,则丢弃概率将降低 connectionDropDecrease。阈值为 connectionMaxTokens * connectionDecreaseRatio。 Java系统属性:zookeeper.connection_throttle_drop_decrease | 默认值为 0.002。 |
| connectionDecreaseRatio | 3.6.0新增,这是用于调整服务器端连接限制程序的参数之一,这是一种基于令牌的速率限制机制,具有可选的概率丢弃功能。此参数定义用于降低丢弃概率的阈值。 对应Java系统属性:zookeeper.connection_throttle_decrease_ratio | 默认值为 0。 |
| zookeeper.connection_throttle_weight_enabled | 3.6.0新增,仅限Java系统属性,节流时是否考虑连接权重。仅当启用连接限制时才有用,即 connectionMaxTokens 大于 0。 | 默认值为 false |
| zookeeper.connection_throttle_global_session_weight | 3.6.0新增,仅限Java系统属性,全局会话的权重。它是全局会话请求通过连接限制程序所需的令牌数。它必须是不小于本地会话权重的正整数。 | 默认值为 3。 |
| zookeeper.connection_throttle_local_session_weight | 3.6.0新增,仅限Java系统属性,本地会话的权重。它是本地会话请求通过连接限制程序所需的令牌数。它必须是一个正整数,不大于全局会话或续订会话的权重。 | 默认值为 1。 |
| zookeeper.connection_throttle_renew_session_weight | 3.6.0新增,仅限Java系统属性,续订会话的权重。它也是重新连接请求通过限制器所需的令牌数。它必须是不小于本地会话权重的正整数。 | 默认值为 2。 |
| clientPortListenBacklog | 3.4.14, 3.5.5, 3.6.0新增,ZooKeeper 服务器套接字的套接字积压长度。这将控制将在服务器端排队等待 ZooKeeper 服务器处理的请求数。超过此长度的连接将收到网络超时(30 秒),这可能会导致 ZooKeeper 会话过期问题。默认情况下,此值为 unset (),在 Linux 上,它使用 backlog 。此值必须为正数。 | |
| serverCnxnFactory | 指定 ServerCnxnFactory 实现。 Java系统属性:zookeeper.serverCnxnFactory | 默认值为NettyServerCnxnFactory``NIOServerCnxnFactory |
| flushDelay | 延迟刷新提交日志的时间(以毫秒为单位)。不影响 maxBatchSize 定义的限制。具有高写入速率的集成可能会看到吞吐量提高,值为 10-20 毫秒。 Java系统属性:zookeeper.flushDelay | 默认情况下禁用(值为 0)。 |
| maxWriteQueuePollTime | 如果启用了 flushDelay,这将确定在没有新请求排队的情况下刷新之前等待的时间(以毫秒为单位)。 Java系统属性:zookeeper.maxWriteQueuePollTime | 默认设置为 flushDelay/3(默认隐式禁用)。 |
| maxBatchSize | 在触发刷新提交日志之前,服务器中允许的事务数。不影响 flushDelay 定义的限制。 Java系统属性:zookeeper.maxBatchSize | 默认值为 1000。 |
| enforceQuota | 强制执行配额检查。当启用并且客户端超过 znode 下的总字节数或子计数限制配额时,服务器将拒绝请求并强制回复客户端 QuotaExceededException。 | 默认值为:false。 |
| requestThrottleLimit | 3.6.0新增,在 RequestThrottler 开始停止之前允许的未完成请求总数。设置为 0 时,将禁用限制。 Java系统属性:zookeeper.request_throttle_max_requests | 默认值为 0。 |
| requestThrottleStallTime | 3.6.0新增,线程可能等待通知可以继续处理请求的最长时间(以毫秒为单位)。 Java系统属性:zookeeper.request_throttle_stall_time | 默认值为 100。 |
| requestThrottleDropStale | 3.6.0新增,启用后,限制器将丢弃过时的请求,而不是将它们发出到请求管道。过时请求是由现已关闭的连接发送的请求,或请求延迟将高于 sessionTimeout 的请求。 Java系统属性:request_throttle_drop_stale | 默认值为 true。 |
| requestStaleLatencyCheck | 启用后,如果请求延迟高于其关联的会话超时,则将请求视为过时。默认情况下禁用。 Java系统属性:zookeeper.request_stale_latency_check | |
| requestStaleConnectionCheck | 3.6.0新增,启用后,如果请求的连接已关闭,则该请求被视为过时。默认启用。 Java系统属性:zookeeper.request_stale_connection_check | |
| zookeeper.request_throttler.shutdownTimeout | 3.6.0新增,仅限Java系统属性。RequestThrottler 在关闭期间等待请求队列耗尽的时间(以毫秒为单位),然后强制关闭。 | 默认值为 10000。 |
| advancedFlowControlEnabled | 根据 ZooKeeper 流水线的状态,在 netty 中使用精确的流量控制,避免直接缓冲区 OOM。它将禁用 Netty 中的AUTO_READ。 Java系统属性:zookeeper.netty.advancedFlowControl.enabled | |
| enableEagerACLCheck | 设置为“true”时,在将请求发送到仲裁之前,对每个本地服务器上的写入请求启用预先 ACL 检查。 Java系统属性:zookeeper.enableEagerACLCheck | 默认值为“false”。 |
| maxConcurrentSnapSyncs | 领导者或追随者可以同时提供的最大快照同步数。 Java系统属性:zookeeper.leader.maxConcurrentSnapSyncs | 默认值为 10。 |
| maxConcurrentDiffSyncs | 领导者或追随者可以同时服务的最大差异同步数。 Java系统属性: zookeeper.leader.maxConcurrentDiffSyncs | 默认值为 100。 |
| digest.enabled | 3.6.0新增功能,添加了摘要功能,用于在从磁盘加载数据库、追赶和跟随 leader 时检测 ZooKeeper 内部的数据不一致。 Java系统属性:zookeeper.digest.enabled | |
| snapshot.compression.method | 3.6.0新增,此属性控制 ZooKeeper 在将快照存储在磁盘上之前是否应压缩快照。 可选值有三个: 1)"":已禁用(无快照压缩)。这是默认行为。 2)gz 3)snappy Java系统属性:zookeeper.snapshot.compression.method | "" |
| snapshot.trust.empty | 3.5.6新增,此属性控制 ZooKeeper 是否应将丢失的快照文件视为无法恢复的致命状态。设置为 true 以允许 ZooKeeper 服务器在没有快照文件的情况下进行恢复。这应该只在从旧版本的 ZooKeeper(3.4.x,3.5.3 之前)升级期间设置,其中 ZooKeeper 可能只有事务日志文件,但没有快照文件。如果在升级过程中设置了该值,建议在升级后将该值设置回 false,并重新启动 ZooKeeper 进程,以便 ZooKeeper 在恢复过程中可以继续进行正常的数据一致性检查。 | 默认值为 false。 |
| audit.enable | 3.6.0新增,默认情况下,审核日志处于禁用状态。设置为“true”以启用它。 Java系统属性:zookeeper.audit.enable | 默认值为“false”。 |
| audit.impl.class | 3.6.0新增,用于实现审计记录器的类。默认情况下,基于logback的审计记录器org.apache.zookeeper.audit 。使用 Slf4jAuditLogger。 Java系统属性: zookeeper.audit.impl.class | |
| largeRequestMaxBytes | 3.6.0新增,所有正在进行的大型请求的最大字节数。如果即将到来的大型请求导致超出限制,则连接将关闭。 Java系统属性:zookeeper.largeRequestMaxBytes | 默认值为 100 * 1024 * 1024。 |
| largeRequestThreshold | 3.6.0新增,超过该阈值后,请求被视为大型请求的大小阈值。如果为 -1,则所有请求都被视为小请求,从而有效地关闭大请求限制。 Java系统属性:zookeeper.largeRequestThreshold | 默认值为 -1。 |
| outstandingHandshake.limit | 3.6.0新增,ZooKeeper 中可能存在的最大动态 TLS 握手连接数,超过此限制的连接将在开始握手之前被拒绝。此设置不会限制最大 TLS 并发性,但有助于避免在动态 TLS 握手过多时由于 TLS 握手超时而导致的羊群效应。将其设置为 250 之类的值足以避免羊群效应。 Java系统属性: zookeeper.largeRequestThreshold | |
| netty.server.earlyDropSecureConnectionHandshakes | 如果 ZooKeeper 服务器未完全启动,请在执行 TLS 握手之前断开 TCP 连接。这对于防止在重新启动后用许多并发 TLS 握手淹没服务器非常有用。请注意,如果启用此标志,则服务器在未完全启动时不会响应“ruok”命令。 Java系统属性:zookeeper.netty.server.earlyDropSecureConnectionHandshakes | |
| throttledOpWaitTime | RequestThrottler 队列中将请求标记为受限制的时间。除了将受限制的请求送到它所属的服务器的管道中以保持所有请求的顺序外,不会进行处理。FinalProcessor 将对这些未消化的请求发出错误响应(新错误代码:ZTHROTTLEDOP)。目的是让客户端不要立即重试它们。设置为 0 时,不会限制任何请求。 Java系统属性:zookeeper.throttled_op_wait_time | 默认值为 0。 |
| learner.closeSocketAsync | 3.7.0新增,启用后,学习者将异步关闭仲裁套接字。 这对于 TLS 连接非常有用,在这些连接中,关闭套接字可能需要很长时间、阻塞关闭过程、可能延迟新的领导者选举以及使仲裁不可用。异步关闭套接字可以避免阻塞关闭过程,尽管套接字关闭时间很长,并且可以在套接字关闭时启动新的领导者选举。 Java系统属性:zookeeper.learner.closeSocketAsync learner.closeSocketAsync(为向后兼容而添加) | 默认值为 false。 |
| leader.closeSocketAsync | 3.7.0新增,启用后,领导者将异步关闭仲裁套接字。 这对于关闭套接字可能需要很长时间的 TLS 连接非常有用。如果由于 SyncLimitCheck 失败而在 ping() 中启动断开跟随程序的连接,则较长的套接字关闭时间将阻止向其他跟随程序发送 ping。如果不接收 ping,其他关注者将不会向领导者发送会话信息,这会导致会话过期。将此标志设置为 true 可确保定期发送 ping。 Java系统属性:zookeeper.leader.closeSocketAsync leader.closeSocketAsync(为向后兼容而添加) | 默认值为 false。 |
| learner.asyncSending | 3.7.0新增,Learner 中的发送和接收数据包是在关键部分同步完成的。不合时宜的网络问题可能导致关注者挂起(请参阅 ZOOKEEPER-3575 和 ZOOKEEPER-4074)。新设计将 Learner 中的发送数据包移动到单独的线程,并异步发送数据包。使用此参数 (learner.asyncSending) 启用新设计。 Java系统属性:zookeeper.learner.asyncSending learner.asyncSending(为向后兼容而添加) | 默认值为 false。 |
| forward_learner_requests_to_commit_processor_disabled | 设置此属性后,来自学习者的请求不会排队到 CommitProcessor 队列,这将有助于节省资源和 leader 上的 GC 时间。 Java系统属性:zookeeper.forward_learner_requests_to_commit_processor_disabled | 默认值为 false。 |
| serializeLastProcessedZxid.enabled | 3.9.0新增,如果启用,ZooKeeper 会在快照时序列化 lastProcessedZxid,并在还原时对其进行反序列化。需要启用才能通过管理服务器命令执行快照和还原,因为没有快照文件名来提取 lastProcessedZxid。 Java系统属性:zookeeper.serializeLastProcessedZxid.enabled | 默认值为 true。 |
3)集群配置
当集群化部署zookeeper时,以下是支持的配置项:
| 配置项 | 含义 | 默认值 |
|---|---|---|
| electionAlg | 要使用的选举算法实现类。可选项有以下几种: 1)"1":对应于未经身份验证的基于 UDP 的快速领导者选举版本 2)"2":对应于经过身份验证的基于 UDP 的快速领导者选举版本 3)"3":对应于基于 TCP 的快速领导者选举版本。 算法 3 在 3.2.0 中是默认的,算法1和2在3.4.0已弃用,以前的版本(3.0.0 和 3.1.0)也使用算法 1 和 2。由于 3.6.0 只有 FastLeaderElection 可用,因此在升级时,必须关闭所有服务器并使用 electionAlg=3 重新启动它们(或从配置文件中删除该行)。 | |
| maxTimeToWaitForEpoch | 3.6.0新增,激活领导者时等待投票者投票的最长时间。 如果领导者收到来自其投票者之一的 LOOKING 通知,并且它没有收到来自 maxTimeToWaitForEpoch 内多数人的投票数据包。则它将转到 LOOKING 并再次选举领导者。 这可以进行调整以减少仲裁或服务器不可用时间。可以设置为比 initLimit * tickTime 小得多。在跨数据中心环境中,可以将其设置为类似 2 秒的值。 Java系统属性:zookeeper.leader.maxTimeToWaitForEpoch | |
| initLimit | 初始通信时限,在最开始实现通信时,即初始化连接时,Leader会同步到所有Follower,这个同步的过程所用的时限即为初始通信时限。集群中的Follower和Leader之间初始连接时能容忍的最多心跳数。如果 ZooKeeper 管理的数据量很大,则根据需要增加此值。 | 10(此时限的值为tickTime的倍数,10表示时限为10*2000毫秒(20秒)) |
| connectToLearnerMasterLimit | 允许追随者在领导人选举后连接到领导人的时间量,单位为ticks(请参阅tickTime)。默认为initLimit的值。当initLimit很高时使用,这样连接到领导者不会导致更高的超时。 Java系统属性:zookeeper.connectToLearnerMasterLimit | |
| leaderServes | Leader 是否也接受客户端连接。为了以读取吞吐量为代价获得更高的更新吞吐量,可以将领导者配置为不接受客户端并专注于协调。此选项的默认值为 yes,这意味着领导者将接受客户端连接。当一个集群中有三个以上的 ZooKeeper 服务器时,强烈建议打开领导者选择。 Java系统属性:zookeeper.leaderServes | 默认值为“yes”。 |
| server.x | 构成 ZooKeeper 集合的服务器,格式为:[hostname]:nnnnn[:nnnnn]。当服务器启动时,它通过在数据目录中查找文件 myid 来确定它是哪个服务器。该文件包含服务器编号(ASCII),并且它应该与server.x中的x匹配。 客户端使用的构成 ZooKeeper 服务器的服务器列表必须与每个 ZooKeeper 服务器拥有的 ZooKeeper 服务器列表匹配,有两个端口号 nnnnn。第一个追随者用于与领导者建立联系,第二个追随者用于领导者选举。如果要在一台计算机上测试多个服务器,则可以对每个服务器使用不同的端口。 从 ZooKeeper 3.6.0 开始,可以为每个 ZooKeeper 服务器指定多个地址(参见 ZOOKEEPER-3188)。但是要支持这个属性,需要设置multiAddress.enabled=true,多地址支持能提高zk整体可用性,当服务器使用多个物理网络接口时,ZooKeeper 能够在所有接口上绑定,并在发生网络错误时动态切换到可用接口。 可以在配置中使用竖线字符指定不同的地址。 示例: server.1=zoo1-net1:2888:3888|zoo1-net2:2889:3889 server.2=zoo2-net1:2888:3888|zoo2-net2:2889:3889 server.3=zoo3-net1:2888:3888|zoo3-net2:2889:3889 | |
| syncLimit | 集群中folower跟leader之间的请求和应答最多能容忍的心跳数,计算方式与initLimit相同,在运行时Leader通过心跳检测与Follower进行通信。如果超过syncLimit*tickTime 的时间还未收到响应,则认定该Follower宕机,会被集群放弃 | 5 |
| group.x | 启用分层仲裁结构。格式是nnnnn[:nnnnn] 。x“是组标识符,”=“符号后面的数字对应于服务器标识符。分配的左侧是以冒号分隔的服务器标识符列表。 请注意,组必须是不相交的,并且所有组的并集必须是 ZooKeeper 集合。 | |
| weight.x | 格式是nnnnn :,它与“group”一起使用,在形成仲裁时为服务器分配权重。这样的值对应于投票时服务器的权重。ZooKeeper 有几个部分需要投票,例如领导者选举和原子广播协议。默认情况下,服务器的权重为 1。如果配置定义了组,但未定义权重,则值 1 将分配给所有服务器。 | |
| cnxTimeout | 领导者选举通知打开连接的超时时间设置。以秒为单位,仅当使用 electionAlg 3 时才适用。 Java系统属性:zookeeper.cnxTimeout | 5 |
| quorumCnxnTimeoutMs | 领导者选举通知连接的读取超时时间设置。以秒为单位,仅当使用 electionAlg 3 时才适用。 Java系统属性:zookeeper.quorumCnxnTimeoutMs | 默认值为 -1,将使用 syncLimit * tickTime 作为超时时间设置。 |
| standaloneEnabled | 3.5.0新增,在3.5.0之前我们可以以单机模式或以分布式模式运行ZK。他们是不同的实现,并且在运行时切换是不可能的。默认(为了向后兼容)standaloneEnabled被设置成true。使用这个默认值的结果是如果启动一个单独的服务端集群将不会起来,并且如果启动多于一个服务端它将不允许缩小到小于两个参与者。 有了这个设置可以启动只包含一个参与者的集群,并且可以动态地增加更多服务端。相似地,它也可以缩小一个群集到只有一个参考者,通过移除服务端。因为运行在分布式模式允许更多灵活性,我们建议设置这个标识为false | 默认true |
| reconfigEnabled | 3.5.3新增,这将控制动态重新配置功能的启用或禁用。启用该功能后,用户可以通过 ZooKeeper 客户端 API 或通过 ZooKeeper 命令行工具执行重新配置操作,前提是用户有权执行此类操作。禁用该功能后,任何用户(包括超级用户)都无法执行重新配置。任何重新配置的尝试都将返回错误。 “reconfigEnabled”选项可以设置为服务器配置文件的“reconfigEnabled=false”或“reconfigEnabled=true”,或使用QuorumPeerConfig的setReconfigEnabled方法。 注意:如果存在,则该值应在整个集群中的每个服务器上保持一致,在某些服务器上将该值设置为 true,在其他服务器上将该值设置为 false 将导致不一致的行为,具体取决于被选为领导者的服务器。如果领导者设置为“reconfigEnabled=true”,则集合将启用重新配置功能。如果领导者设置为“reconfigEnabled=false”,则集合将禁用重新配置功能。因此,建议在集群中的服务器之间使用一致的“reconfigEnabled”值。 | false |
| 4lw.commands.whitelist | 3.5.3新增,用户要使用的逗号分隔的四个字母单词命令白名单列表。必须在此列表中放置有效的四个字母单词命令,否则 ZooKeeper 服务器将不会启用该命令。默认情况下,白名单仅包含 zkServer.sh 使用的“srvr”命令。默认情况下,其余的四个字母的单词命令处于禁用状态,尝试使用它们将获得响应“......未执行,因为它不在白名单中。下面是一个配置示例,该配置启用 stat、ruok、conf 和 isro 命令,同时禁用 Four Letter Words 命令的其余部分: 4lw.commands.whitelist=stat, ruok, conf, isro 如果确实需要默认启用所有四个字母的单词命令,则可以使用星号选项,这样就不必在列表中逐个包含每个命令。例如,这将启用所有四个字母的单词命令: 4lw.commands.whitelist=* | |
| tcpKeepAlive | 3.5.4新增,将此项设置为 true 会在仲裁成员用于执行选举的套接字上设置 TCP keepAlive 标志,这将允许仲裁成员之间的连接在网络基础结构可能中断时保持正常运行。某些 NAT 和防火墙可能会因长时间运行或空闲连接而终止或丢失状态。启用此选项依赖于操作系统级别设置才能正常工作,请查看操作系统中有关 TCP keepalive 的选项以获取更多信息。 Java系统属性:zookeeper.tcpKeepAlive | false |
| clientTcpKeepAlive | 3.6.1新增,将此设置为 true 会在客户端套接字上设置 TCP keepAlive 标志。某些损坏的网络基础结构可能会丢失从关闭客户端发送的 FIN 数据包,这些从未关闭的客户端套接字会导致操作系统资源泄漏,启用此选项会通过空闲检查终止这些僵尸套接字。启用此选项依赖于操作系统级别设置才能正常工作,请查看操作系统中有关 TCP keepalive 的选项以获取更多信息。 请注意它与 tcpKeepAlive 之间的区别。 它适用于客户端套接字,而 tcpKeepAlive 适用于仲裁成员使用的套接字。目前,此选项仅在使用默认值 NIOServerCnxnFactory时可用。Java系统属性:zookeeper.clientTcpKeepAlive | false |
| electionPortBindRetry | 当 Zookeeper 服务器无法绑定 leader 选举端口时,该属性设置最大重试计数。此类错误可以是暂时的和可恢复的,例如 ZOOKEEPER-3320中描述的 DNS 问题,也可以是不可重试的,例如已在使用的端口在发生暂时性错误的情况下,此属性可以提高 Zookeeper 服务器的可用性并帮助其自我恢复。 在容器环境中,尤其是在 Kubernetes 中,应增加此值或将其设置为 0(无限重试),以解决与 DNS 名称解析相关的问题。 Java系统属性:zookeeper.electionPortBindRetry | 3 |
| observer.reconnectDelayMs | 当观察者失去与领导者的连接时,它会等待指定的值,然后再尝试与领导者重新连接,这样整个观察者队列就不会尝试运行领导者选举并立即重新连接到领导者。默认值为 0 毫秒。 Java系统属性:zookeeper.observer.reconnectDelayMs | 0 |
| observer.election.DelayMs | 在断开连接时延迟观察者参与领导人选举,以防止在此过程中对投票对等方产生意外的额外负载。默认值为200毫秒 Java系统属性:zookeeper.observer.election.DelayMs | 200 |
| localSessionsEnabled 和localSessionsUpgradingEnabled | 3.5新增,其默认值都为 false。通过设置 localSessionsEnabled=true 来打开本地会话功能。打开 localSessionsUpgradingEnabled可以根据需要自动将本地会话升级为全局会话(例如创建临时节点),这仅在启用 localSessionsEnabled 时才生效。 | false |
| observerMasterPort | 设置这个标识为false指示系统以分布式运行,即使集群里只有一个参与者。为了实现这样配置文件应该包含:用于侦听Observer 连接的端口;即Observer 尝试连接到的端口 |
4)加密、身份验证、授权配置
| 配置项 | 含义 | 默认值 |
|---|---|---|
| DigestAuthenticationProvider.enabled | 3.7新增,确定是否启用身份验证提供程序。默认值为 true 以实现向后兼容性,但如果未使用,最好禁用此提供程序,因为它可能会导致审核日志中出现误导性日志( ZOOKEEPER-3979) Java系统属性:zookeeper.DigestAuthenticationProvider.enabled | true |
| DigestAuthenticationProvider.superDigest | 3.2新增,是否使 ZooKeeper 集群管理员能够以“超级”用户身份访问 znode 层次结构。默认情况下,此功能处于禁用状态 。特别是,对于经过身份验证为 super 的用户,不会进行 ACL 检查。org.apache.zookeeper.server.auth.DigestAuthenticationProvider可用于生成 superDigest,使用一个参数“super:”调用它。在启动集成的每个服务器时,提供生成的“super:”作为系统属性值。向 ZooKeeper 服务器(从 ZooKeeper 客户端)进行身份验证时,传递 “digest” 方案和 “super:” 的 authdata。请注意,摘要式身份验证以明文形式将 authdata 传递给服务器,谨慎的做法是仅在 localhost(而不是通过网络)或加密连接上使用此身份验证方法。 Java系统属性:zookeeper.DigestAuthenticationProvider.superDigest | disabled |
| DigestAuthenticationProvider.digestAlg | 设置 ACL 摘要算法。默认值为:SHA1。将来将因安全问题而弃用。在所有服务器中必须将此属性设置为相同的值。 如何支持其他更多算法? 1)通过指定命令 security.provider.<n>=<provider class name>`.`修改 `$JAVA_HOME/jre/lib/security/java.security`下的配置文件 java.security 示例: zookeeper.DigestAuthenticationProvider.digestAlg=RipeMD160 security.provider.3=org.bouncycastle.jce.provider.BouncyCastleProvider 2)然后将 JAR 文件复制到$JAVA_HOME/jre/lib/ext/ 。 示例:copy bcprov-jdk18on-1.60.jar to $JAVA_HOME/jre/lib/ext/ 如何从一种摘要算法迁移到另一种摘要算法? 1)迁移到新算法时重新生成superDigest 2)SetAcl对于已经具有旧算法的摘要身份验证的 znode。 | SHA1 |
| X509AuthenticationProvider.superUser | 一种支持 SSL 的方式,使 ZooKeeper 整体管理员能够以“super”用户身份访问 znode 层次结构。当此参数设置为 X500 主体名称时,只有具有该主体的经过身份验证的客户端才能绕过 ACL 检查并拥有对所有 znode 的完全权限。 Java系统属性:zookeeper.X509AuthenticationProvider.superUser | |
| zookeeper.superUser | 类似于zookeeper.X509AuthenticationProvider.superUser,但对于基于 SASL 的登录是通用的。它存储可以作为“超级”用户访问 znode 层次结构的用户的名称。可以使用 zookeeper.superUser 指定多个 SASL 超级用户。例如:.zookeeper.superUser.1=...Java系统属性:zookeeper.superUser | |
| ssl.authProvider | 指定用于安全客户端身份验证的 org.apache.zookeeper.auth.X509AuthenticationProvider的子类。这在不使用 JKS 的证书密钥基础结构中很有用。可能需要扩展 javax.net.ssl.X509KeyManager 和 javax.net.ssl.X509TrustManager才能从 SSL 堆栈中获取所需的行为。要将 ZooKeeper 服务器配置为使用自定义提供程序进行身份验证,请为自定义 AuthenticationProvider 选择方案名称并设置属性 zookeeper.authProvider.scheme]设置为自定义实现的完全限定类名。这会将提供程序加载到 ProviderRegistry 中。然后设置此属性 zookeeper.ssl.authProvider=[scheme]*该提供程序将用于安全身份验证。 Java系统属性:zookeeper.ssl.authProvider | |
| zookeeper.ensembleAuthName | 3.6.0新增,指定以逗号分隔的集合的有效名称/别名列表。客户端可以提供它打算连接的集合名称作为方案“ensemble”的凭据。EnsembleAuthenticationProvider 将根据接收连接请求的集合的名称/别名列表检查凭据。如果凭据不在列表中,则连接请求将被拒绝。这样可以防止客户端意外连接到错误的集合。 Java系统属性:zookeeper.ensembleAuthName | |
| sessionRequireClientSASLAuth | 3.6.0新增,设置为 true 时,ZooKeeper 服务器将仅接受来自已通过 SASL 向服务器进行身份验证的客户端的连接和请求。未配置SASL身份验证的客户端,或配置了SASL但身份验证失败(即凭据无效)的客户端将无法与服务器建立会话。在这种情况下,将提供键入的错误代码 (-124),此后 Java 和 C 客户端都将关闭与服务器的会话,而无需进一步尝试重新尝试重新连接。此配置是 enforce.auth.enabled=true 和 enforce.auth.scheme=sasl 的简写。默认情况下,此功能处于禁用状态。想要选择加入的用户可以通过将 sessionRequireClientSASLAuth 设置为 true 来启用该功能。 此功能会否决 zookeeper.allowSaslFailedClients 选项,因此,即使将服务器配置为允许未通过 SASL 身份验证的客户端登录,如果启用此功能,客户端也无法与服务器建立会话。 Java系统属性:zookeeper.sessionRequireClientSASLAuth | |
| enforce.auth.enabled | 3.7.0新增,设置为 true 时,ZooKeeper 服务器将仅接受来自已通过配置的身份验证方案向服务器进行身份验证的客户端的连接和请求。可以使用属性 enforce.auth.schemes 配置身份验证方案。未配置在服务器上配置的任何身份验证方案或已配置但身份验证失败(即凭据无效)的客户端将无法与服务器建立会话。在这种情况下,将提供键入的错误代码 (-124),此后 Java 和 C 客户端都将关闭与服务器的会话,而无需进一步尝试重新尝试重新连接。 默认情况下,此功能处于禁用状态。想要选择加入的用户可以通过将 enforce.auth.enabled 设置为 true 来启用该功能。 当 enforce.auth.enabled=true和 enforce.auth.schemes=sasl 时,zookeeper.allowSaslFailedClients 配置将被否决。因此,即使服务器配置为允许未通过 SASL 身份验证的客户端登录,如果使用 sasl 作为身份验证方案启用此功能,客户端也无法与服务器建立会话。 Java系统属性:zookeeper.enforce.auth.enabled | |
| enforce.auth.schemes | 3.7.0新增,以逗号分隔的身份验证方案列表。在执行任何 zookeeper 操作之前,必须使用至少一种身份验证方案对客户端进行身份验证。仅当 enforce.auth.enabled 为 true 时,才使用此属性。 Java系统属性:zookeeper.enforce.auth.schemes | |
| sslQuorum | 3.5.5新增,启用加密的仲裁通信。缺省值为false 。启用此功能时,还请考虑启用 leader.closeSocketAsync 和 learner.closeSocketAsync,以避免在关闭 SSL 连接时出现与套接字关闭时间可能过长相关的问题。 Java系统属性:zookeeper.sslQuorum | |
| ssl.keyStore.location ssl.keyStore.password ssl.quorum.keyStore.location ssl.quorum.keyStore.password | 3.5.5新增,指定 Java 密钥库的文件路径,该密钥库包含用于客户机和仲裁 TLS 连接的本地凭证,以及用于解锁文件的密码。 对应Java系统属性: zookeeper.ssl.keyStore.location zookeeper.ssl.keyStore.password zookeeper.ssl.quorum.keyStore.location zookeeper.ssl.quorum.keyStore.password | |
| ssl.keyStore.passwordPath ssl.quorum.keyStore.passwordPath | 3.8.0新增,指定包含密钥库密码的文件路径。从文件中读取密码优先于显式密码属性。 Java系统属性: zookeeper.ssl.keyStore.passwordPath zookeeper.ssl.quorum.keyStore.passwordPath | |
| ssl.keyStore.type ssl.quorum.keyStore.type | 3.5.5新增,指定客户机密钥库和仲裁密钥库的文件格式。值:JKS、PEM、PKCS12 或 null(按文件名检测)。默认值:null。 3.5.10、3.6.3、3.7.0 中的新功能:添加了 BCFKS 格式。 Java 系统属性: zookeeper.ssl.keyStore.type zookeeper.ssl.quorum.keyStore.type | null |
| ssl.trustStore.location ssl.trustStore.password ssl.quorum.trustStore.location ssl.quorum.trustStore.password | 3.5.5新增,指定 Java 信任库的文件路径,其中包含要用于客户机和仲裁 TLS 连接的远程凭证,以及用于解锁文件的密码。 Java 系统属性: zookeeper.ssl.trustStore.location zookeeper.ssl.trustStore.password zookeeper.ssl.quorum.trustStore.location zookeeper.ssl.quorum.trustStore.password | |
| ssl.trustStore.passwordPath ssl.quorum.trustStore.passwordPath | 3.8.0新增,指定包含信任库密码的文件路径。 从文件中读取密码优先于显式密码属性。 Java 系统属性: zookeeper.ssl.trustStore.passwordPath zookeeper.ssl.quorum.trustStore.passwordPath | |
| ssl.trustStore.type ssl.quorum.trustStore.type | 3.5.5 中的新增功能:指定客户端和仲裁 trustStore 的文件格式。 值:JKS、PEM、PKCS12 或 null(按文件名检测)。默认值:null。 3.5.10、3.6.3、3.7.0 中的新功能:添加了 BCFKS 格式。 Java 系统属性:zookeeper.ssl.trustStore.type zookeeper.ssl.quorum.trustStore.type | null |
| ssl.protocol ssl.quorum.protocol | 3.5.5 中新增:指定要在客户端和仲裁 TLS 协商中使用的协议。 默认值:TLSv1.2。 Java 系统属性:zookeeper.ssl.protocol 和 zookeeper.ssl.quorum.protocol | TLSv1.2 |
| ssl.enabledProtocols ssl.quorum.enabledProtocols | 3.5.5 中新增:指定客户端和仲裁 TLS 协商中启用的协议。 默认值:属性值protocol。Java系统属性:zookeeper.ssl.enabledProtocols h和zookeeper.ssl.quorum.enabledProtocols | |
| ssl.ciphersuites ssl.quorum.ciphersuites | 3.5.5 中新增:指定要在客户端和仲裁 TLS 协商中使用的已启用密码套件。默认值:启用的密码套件取决于所使用的 Java 运行时版本。 Java系统属性:zookeeper.ssl.ciphersuites 和zookeeper.ssl.quorum.ciphersuites | |
| ssl.context.supplier.class ssl.quorum.context.supplier.class | 3.5.5 中的新功能:指定用于在客户端和仲裁 SSL 通信中创建 SSL 上下文的类。这允许您使用自定义 SSL 上下文并实现以下方案: 1)使用硬件密钥库,使用 PKCS11 或类似工具加载。 2)您无权访问软件密钥库,但可以从其容器中检索已构造的 SSLContext。默认值:null | |
| ssl.hostnameVerification ssl.quorum.hostnameVerification | 3.5.5 中的新功能:指定是否在客户端和仲裁 TLS 协商过程中启用主机名验证。禁用它仅建议用于测试目的。默认值:true Java 系统属性:zookeeper.ssl.hostnameVerification 和 zookeeper.ssl.quorum.hostnameVerification | true |
| ssl.crl ssl.quorum.crl | 3.5.5 中的新功能:指定是否在客户端和仲裁 TLS 协议中启用证书吊销列表。默认值:false Java 系统属性:zookeeper.ssl.crl 和 zookeeper.ssl.quorum.crl | false |
| ssl.ocsp ssl.quorum.ocsp | 3.5.5 中的新增功能:指定是否在客户端和仲裁 TLS 协议中启用联机证书状态协议。 默认值:false Java 系统属性:zookeeper.ssl.ocsp 和 zookeeper.ssl.quorum.ocsp | false |
| ssl.clientAuth ssl.quorum.clientAuth | 在 3.5.5 中添加,但在 3.5.7 之前废弃:指定用于验证来自客户端的 ssl 连接的选项。有效值为: 1) “none”: 服务器不会请求客户端身份验证 2) “want”: 服务器将“请求”客户端身份验证 3)“need”: 服务器将“需要”客户端身份验证 Java 系统属性:zookeeper.ssl.clientAuth 和 zookeeper.ssl.quorum.clientAuth | need |
| ssl.handshakeDetectionTimeoutMillis ssl.quorum.handshakeDetectionTimeoutMillis | 3.5.5 中的新功能:待定 Java 系统属性:zookeeper.ssl.handshakeDetectionTimeoutMillis 和 zookeeper.ssl.quorum.handshakeDetectionTimeoutMillis | |
| ssl.sslProvider | 3.9.0新增,启用 TLS 时,允许在客户端-服务器通信中选择 SSL 提供程序。在 3.9.0 版本中,ZooKeeper 中添加了 Netty-tcnative 原生库,这允许我们在支持的平台上使用 OpenSSL 等原生 SSL 库。请参阅 Netty-tcnative 文档中的可用选项。默认值为“JDK”。 Java系统属性:zookeeper.ssl.sslProvider | JDK |
| sslQuorumReloadCertFiles | 3.5.5、3.6.0 中的新功能:当文件系统上的证书发生更改时,允许重新加载仲裁 SSL 密钥库和信任库,而无需重新启动 ZK 进程。默认值:false | false |
| client.certReload | 3.7.2、3.8.1、3.9.0 中的新功能:当文件系统上的证书发生更改时,允许重新加载客户端 SSL keyStore 和 trustStore,而无需重新启动 ZK 进程。默认值:false。 Java系统属性:zookeeper.client.certReload | false |
| client.portUnification | 指定客户端端口应接受 SSL 连接(使用与安全客户端端口相同的配置)。默认值:false。 Java系统属性:zookeeper.client.portUnification | false |
| authProvider | 可以为 ZooKeeper 指定多个身份验证提供程序类。通常使用此参数来指定 SASL 身份验证提供程序,例如:authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider Java系统属性:zookeeper.authProvider | |
| kerberos.removeHostFromPrincipal | 您可以指示 ZooKeeper 在身份验证期间从客户端主体名称中删除主机。(例如,zk/myhost@EXAMPLE.COM 客户端主体将在 ZooKeeper 中 zk@EXAMPLE.COM 进行身份验证)默认值:false Java系统属性:zookeeper.kerberos.removeHostFromPrincipal | false |
| kerberos.removeRealmFromPrincipal | 可以指示 ZooKeeper 在身份验证期间从客户端主体名称中删除领域。(例如,zk/myhost@EXAMPLE.COM 客户端主体将在 ZooKeeper 中作为 zk/myhost 进行身份验证)默认值:false Java 系统属性:zookeeper.kerberos.removeRealmFromPrincipal | false |
| kerberos.canonicalizeHostNames | 3.7.0 中的新增功能:指示 ZooKeeper 规范化从 server.x 行中提取的服务器主机名。这允许使用例如 记录到配置文件中的引用服务器,同时仍启用仲裁成员之间的 SASL Kerberos 身份验证。它实质上等同于客户端的 zookeeper.sasl.client.canonicalize.hostname 属性的仲裁。默认值为 false,以便向后兼容。 Java 系统属性:zookeeper.kerberos.canonicalizeHostNames | false |
| multiAddress.enabled | 从 ZooKeeper 3.6.0 开始,还可以为每个 ZooKeeper 服务器实例指定多个地址(当可以在集群中并行使用多个物理网络接口时,这可以提高可用性)。将此参数设置为 true 将启用此功能。请注意,如果旧 ZooKeeper 集群的版本低于 3.6.0,则无法在滚动升级期间启用此功能。默认值为 false。 Java系统属性:zookeeper.multiAddress.enabled | false |
| multiAddress.reachabilityCheckTimeoutMs | 3.6.0 中的新功能:从 ZooKeeper 3.6.0 开始,您还可以为每个 ZooKeeper 服务器实例指定多个地址(当可以在集群中并行使用多个物理网络接口时,这可以提高可用性)。ZooKeeper 将执行 ICMP ECHO 请求或尝试在目标主机的端口 7 (Echo) 上建立 TCP 连接,以查找可访问的地址。仅当您在配置中提供多个地址时,才会发生这种情况。在此属性中,可以设置可访问性检查的超时(以毫秒为单位)。对于不同的地址,检查是并行进行的,因此您在此处设置的超时是通过检查所有地址的可访问性所花费的最长时间。默认值为 1000。 Java系统属性:zookeeper.multiAddress.reachabilityCheckTimeoutMs | 1000 |
| fips-mode | 3.8.2 中的新功能:在 ZooKeeper 中启用 FIPS 兼容模式。如果启用,则将禁用用于主机名验证的定制信任管理器 (ZKTrustManager),以符合 FIPS 要求。因此,主机名验证在仲裁协议中不可用,但仍然可以在客户端-服务器通信中设置。默认值:true (3.9.0+)、false (3.8.x) Java系统属性:zookeeper.fips-mode |
5)性能调优配置
在3.5.0版本对多个子系统进行了重新设计,以提高读取吞吐量。这包括 NIO 通信子系统和请求处理管道(提交处理器)的多线程。NIO 是默认的客户端/服务器通信子系统。其线程模型包括 1 个接受器线程、1-N 个选择器线程和 0-M 套接字 I/O 工作线程。在请求处理管道中,可以将系统配置为一次处理多个读取请求,同时保持相同的一致性保证(同会话先写后读)。提交处理器线程模型包括 1 个主线程和 0-N 个工作线程。
默认值旨在最大限度地提高专用 ZooKeeper 计算机上的读取吞吐量。这两个子系统都需要具有足够数量的线程才能实现峰值读取吞吐量。
| 配置项 | 含义 | 默认值 |
|---|---|---|
| zookeeper.nio.numSelectorThreads | 3.5.0新增,NIO 选择器线程数。至少需要 1 个选择器线程。建议对大量客户端连接使用多个选择器。 仅限Java系统属性:zookeeper.nio.numSelectorThreads | sqrt( number of cpu cores / 2 ) |
| zookeeper.nio.numWorkerThreads | 3.5.0新增,NIO 工作线程数。如果配置了 0 个工作线程,则选择器线程直接执行套接字 I/O。默认值为 CPU 核心数的 2 倍。 仅限Java系统属性:zookeeper.nio.numWorkerThreads | CPU 核心数的 2 倍。 |
| zookeeper.commitProcessor.numWorkerThreads | 3.5.0 中的新功能:提交处理器工作线程数。如果配置了 0 个工作线程,则主线程将直接处理请求。默认值为 cpu 核心数。 仅限Java系统属性:zookeeper.commitProcessor.numWorkerThreads | cpu 核心数。 |
| zookeeper.commitProcessor.maxReadBatchSize | 在切换到处理提交之前,要从 queuedRequests 处理的最大读取大小。如果该值< 0(默认值),则每当有本地写入和待处理提交时,我们都会切换。较高的读取批处理大小将延迟提交处理,从而导致提供过时的数据。如果已知读取以固定大小的批处理到达,则将该批处理大小与此属性的值匹配可以平滑队列性能。由于读取是并行处理的,因此建议将此属性设置为与 zookeeper.commitProcessor.numWorkerThread(默认值为 cpu 内核数)或更低的匹配。 仅限Java系统属性:zookeeper.commitProcessor.maxReadBatchSize | 0 |
| zookeeper.commitProcessor.maxCommitBatchSize | 在处理读取之前要处理的最大提交数。我们将尝试处理尽可能多的远程/本地提交,直到达到此计数。较高的提交批处理大小将延迟读取,同时处理更多提交。较低的提交批处理大小将有利于读取。建议仅在整体处理具有高提交率的工作负载时设置此属性。如果已知写入在设定数量的批处理中到达,则将该批大小与此属性的值匹配可以平滑队列性能。一种通用方法是将此值设置为等于集成大小,以便在处理每个批处理时,当前服务器将概率地处理与其直接客户端之一相关的写入。默认值为“1”。不支持负值和零值。 仅限Java系统属性:zookeeper.commitProcessor.maxCommitBatchSize | 1 |
| znode.container.checkIntervalMs | 3.6.0 中的新增功能:每次检查候选容器和 ttl 节点的时间间隔(以毫秒为单位)。 仅限Java系统属性:znode.container.checkIntervalMs | 60000 |
| znode.container.maxPerMinute | 3.6.0 中的新增功能:每分钟可以删除的最大容器和 ttl 节点数。这样可以防止在容器删除期间出现羊群效应。 仅限 Java 系统属性:znode.container.maxPerMinute | 10000 |
| znode.container.maxNeverUsedIntervalMs | 3.6.0 中的新增功能:保留从未有过任何子项的容器的最大间隔(以毫秒为单位)。应该足够长,以便客户端创建容器,执行任何需要的工作,然后创建子项。默认值为“0”,用于指示从未有过任何子级的容器永远不会被删除。 仅限 Java 系统属性 | 0 |
6)AdminServer 配置
| 配置项 | 含义 | 默认值 |
|---|---|---|
| admin.rateLimiterIntervalInMS | 3.9.0新增,速率限制管理命令保护服务器的时间间隔。默认值为 5 分钟。 Java系统属性:zookeeper.admin.rateLimiterIntervalInMS | 5 |
| admin.snapshot.enabled | 3.9.0新增,用于启用 snapshot 命令的标志。默认值为 true。 Java系统属性:zookeeper.admin.snapshot.enabled | true |
| admin.restore.enabled | 3.9.0新增,用于启用 restore 命令的标志。默认值为 true。 Java系统属性:zookeeper.admin.restore.enabled | true |
| admin.needClientAuth | 3.9.0新增,用于控制是否需要客户端身份验证的标志。使用 x509 身份验证需要 true。默认值为 false。 Java系统属性:zookeeper.admin.needClientAuth | false |
| admin.forceHttps | 3.7.1新增,强制 AdminServer 使用 SSL,从而仅允许 HTTPS 流量。默认为 disabled。覆盖 admin.portUnification 设置。 Java系统属性:zookeeper.admin.forceHttps | disabled |
| admin.portUnification | 3.6.0新增,启用管理端口以接受 HTTP 和 HTTPS 流量。 Java系统属性:zookeeper.admin.portUnification | disabled |
| admin.enableServer | 3.5.0新增,设置为“false”以禁用 AdminServer。默认情况下,AdminServer 处于启用状态。 | false |
| admin.serverAddress | 3.5.0新增,嵌入式 Jetty 服务器侦听的地址。默认值为 0.0.0.0。 Java系统属性:zookeeper.admin.serverAddress | 0.0.0.0 |
| admin.serverPort | 3.5.0新增,嵌入式 Jetty 服务器侦听的端口。默认值为 8080。 Java系统属性:zookeeper.admin.serverPort | 8080 |
| admin.idleTimeout | 3.5.0新增,设置连接在发送或接收数据之前可以等待的最大空闲时间(以毫秒为单位)。默认值为 30000 毫秒。 Java系统属性:zookeeper.admin.idleTimeout | 30000 |
| admin.commandURL | 3.5.0新增,用于列出和发出相对于根 URL 的命令的 URL。默认为“/commands”。 Java系统属性:zookeeper.admin.commandURL | /commands |
7)指标配置
从 3.6.0 开始,从 3.6.0 开始,ZooKeeper 集成了Prometheus。我们也可以配置不同的指标提供程序,将指标导出到相关的系统。
默认情况下,ZooKeeper 服务器使用AdminServer. and Four Letter Words interface。以下选项用于配置指标。
| 配置项 | 含义 | 默认值 |
|---|---|---|
| metricsProvider.className | 设置为“org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider”以启用 Prometheus.io 导出器。 | |
| metricsProvider.httpHost | 3.8.0 中的新功能:Prometheus.io 导出器将启动 Jetty 服务器并监听此地址,默认为“0.0.0.0” | 0.0.0.0 |
| metricsProvider.httpPort | Prometheus.io 导出器将启动 Jetty 服务器并绑定到此端口,则默认为 7000。Prometheus 端点将是 http://hostname:httPort/metrics。 | 7000 |
| metricsProvider.exportJvmInfo | 如果此属性设置为 true,Prometheus.io 将导出有关 JVM 的有用指标。默认值为 true。 | true |
| metricsProvider.numWorkerThreads | 3.7.1 中的新功能:用于报告 Prometheus 摘要指标的工作线程数。默认值为 1。如果数字小于 1,则将使用主线程。 | 1 |
| metricsProvider.maxQueueSize | 3.7.1 中的新功能:Prometheus 摘要指标报告任务的最大队列大小。默认值为 1000000。 | 1000000 |
| metricsProvider.workerShutdownTimeoutMs | 3.7.1 中的新功能:Prometheus 工作线程关闭的超时时间(以毫秒为单位)。默认值为 1000 毫秒。 | 1000 |
8)netty通信
Netty是一个基于 NIO 的客户端/服务器通信框架,它简化了 java 应用程序网络级通信的许多复杂性(而不是直接使用的 NIO)。此外,Netty框架还内置了对加密(SSL)和身份验证(证书)的支持。在Zookeeper中这些是可选功能,可以单独打开或关闭。
在版本 3.5+ 中,ZooKeeper 服务器可以通过设置环境变量来使用 Netty 而不是 NIO(默认选项)zookeeper.serverCnxnFactory 更改为 org.apache.zookeeper.server.NettyServerCnxnFactory。对于客户端,将 zookeeper.clientCnxnSocket 设置为 org.apache.zookeeper.ClientCnxnSocketNetty。
9)其它配置
| 配置项 | 含义 | 默认值 |
|---|---|---|
| readonlymode.enabled | 3.4.0 中的新增功能(实验性新功能):将此值设置为 true 将启用只读模式服务器支持(默认禁用)。ROM 允许请求 ROM 支持的客户端会话连接到服务器,即使服务器可能已从仲裁中分区。在这种模式下,ROM 客户端仍然可以从 ZK 服务读取值,但无法写入值并查看来自其他客户端的更改。有关详细信息,请参阅 ZOOKEEPER-784。 Java系统属性:readonlymode.enabled | false |
| zookeeper.follower.skipLearnerRequestToNextProcessor | 实验性新功能:当我们的集群具有与 ObserverMaster 连接的观察者时,打开此标志可能有助于您减少 Observer Master 上的一些内存压力。如果您的集群没有任何观察者,或者它们没有与 ObserverMaster 连接,或者您的观察者没有进行太多写入,那么使用此标志将无济于事。目前,此处的更改受到保护,以帮助我们对内存使用更有信心。从长远来看,我们可能希望删除此标志并将其行为设置为默认代码路径。 Java系统属性:zookeeper.follower.skipLearnerRequestToNextProcessor | |
| forceSync | 不安全的选项,使用时要小心。要求在完成更新处理之前将更新同步到事务日志的介质。如果此选项设置为否,则 ZooKeeper 将不需要将更新同步到媒体。 Java系统属性:zookeeper.forceSync | |
| jute.maxbuffer | 不安全的选项,使用时要小心。它指定了可以存储在 znode 中的数据的最大大小。单位为:字节。默认值为 0xfffff(1048575) 字节,或略低于 1M。 如果更改此选项,则必须在所有服务器和客户端上设置系统属性,否则将出现问题。 当客户端的 jute.maxbuffer 大于服务端时,客户端要写入的数据超过服务端的 jute.maxbuffer,服务端会得到 java.io.IOException: Len Error。 当客户端的 jute.maxbuffer 小于服务端,客户端想要读取的数据超过客户端的 jute.maxbuffer 时,客户端会收到 java.io.IOException: Unreasonable length or Packet len is out of range! ZooKeeper 旨在存储大小为千字节的数据。在生产环境中,不建议将此属性增加到超过默认值,原因如下: 大尺寸 znode 会导致不必要的延迟峰值,从而降低吞吐量 大尺寸的 znode 使得 leader 和 follower 之间的同步时间不可预测且不收敛(有时超时),导致仲裁不稳定 仅限Java系统属性:jute.maxbuffer | |
| jute.maxbuffer.extrasize | 不安全的选项,使用时要小心。3.5.7 中的新功能:在处理客户端请求时,ZooKeeper 服务器会在将其持久化为事务之前将一些附加信息添加到请求中。早些时候,此附加信息大小固定为 1024 字节。对于许多方案,特别是 jute.maxbuffer 值大于 1 MB 且请求类型为多个的方案,此固定大小是不够的。为了处理所有场景,额外的信息大小从 1024 字节增加到与 jute.maxbuffer 大小相同,并且还可以通过 jute.maxbuffer.extrasize 进行配置。通常不需要配置此属性,因为默认值是最优化值。 Java系统属性:zookeeper.jute.maxbuffer.extrasize | |
| skipACL | 跳过 ACL 检查。这样可以提高吞吐量,会向所有人开放对数据树的完全访问权限。 Java系统属性:zookeeper.skipACL | |
| quorumListenOnAllIPs | 不安全的选项,使用时要小心。设置为 true 时,ZooKeeper 服务器将侦听来自所有可用 IP 地址的对等方的连接,而不仅仅是配置文件的服务器列表中配置的地址。它会影响处理 ZAB 协议和快速领导者选举协议的连接。默认值为 false。 | false |
| multiAddress.reachabilityCheckEnabled | 不安全的选项,使用时要小心。3.6.0 中的新功能:可以为每个 ZooKeeper 服务器实例指定多个地址(当可以在集群中并行使用多个物理网络接口时,这可以提高可用性)。ZooKeeper 将执行 ICMP ECHO 请求或尝试在目标主机的端口 7 (Echo) 上建立 TCP 连接,以查找可访问的地址。仅当您在配置中提供多个地址时,才会发生这种情况。当您尝试在单台计算机上启动大量(例如 11+)集合成员进行集群测试时,如果遇到某些 ICMP 速率限制(例如在 macOS 上),则可访问性检查可能会失败。 默认值为 true。通过将此参数设置为“false”,可以禁用可访问性检查。请注意,禁用可访问性检查将导致集群在出现网络问题时无法正确重新配置自身,因此建议仅在测试期间禁用。 此参数无效,除非通过设置 multiAddress.enabled=true 来启用 MultiAddress 功能。 Java系统属性:zookeeper.multiAddress.reachabilityCheckEnabled | true |
| zookeeper.messageTracker.BufferSize | 3.6.0新增,该选项使 zookeeper 更易于调试。控制存储在 MessageTracker 中的最大消息数。值应为正整数。默认值为 10。MessageTracker 在 3.6.0 中引入,用于记录服务器(跟随者或观察者)与领导者之间的最后一组消息,当服务器与领导者断开连接时。然后,这些消息集将被转储到 zookeeper 的日志文件中,这将有助于重建断开连接时服务器的状态,并且对于调试目的很有用。 | |
| zookeeper.messageTracker.Enabled | 3.6.0新增,该选项使 zookeeper 更易于调试。设置为“true”时,将使 MessageTracker 能够跟踪和记录消息。默认值为“false”。 |
7、动态配置
ZooKeeper: Because Coordinating Distributed Systems is a Zoo (apache.org)
8、SSL认证
要预先 生成好客户端与服务端的ssl证书keystore和cert,生成步骤可以自行百度。
- a. 修改服务端配置
在配置文件zoo.cfg中将配置项clientPort替换为secureClientPort
#clientPort=2181
secureClientPort=2281并添加如下配置
serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactory
ssl.keyStore.location= path/to/your/KeyStore.jks
ssl.keyStore.password= testpwd
ssl.trustStore.location= path/to/your/TrustStore.jks
ssl.trustStore.password= testpwdb.修改zkCli.sh
修改
bin/zkCli.sh,在该命令行工具脚本文件第70行左右添加如下配置export CLIENT_JVMFLAGS=" -Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty -Dzookeeper.client.secure=true -Dzookeeper.ssl.hostnameVerification=false -Dzookeeper.ssl.keyStore.location=path/to/your/KeyStore.jks -Dzookeeper.ssl.keyStore.password=testpwd -Dzookeeper.ssl.trustStore.location=path/to/your/TrustStore.jks -Dzookeeper.ssl.trustStore.password=testpwd -Dzookeeper.ssl.hostnameVerification=false"至此 服务端操作就全部完成了,可以重启zk节点,使用zkCli.sh脚本登录zk进行crud操作了。
c.客户端操作
在客户端也生成SSL证书相关的keystore和cert,将cert提交给服务端,服务端使用如下命令导入
keytool -import -alias 客户端名字 -file 客户端证书.cer -keystore truststore路径使用服务端提供的cert,同样用上面的指令将证书导入客户端truststore。
上面的导入步骤是将客户端与服务端双方的cert证书导入到对方的truststore文件中去。
完成证书互相导入操作后,使用java原生API连接Zk:
ZKClientConfig config = new ZKClientConfig();
config.setProperty("zookeeper.clientCnxnSocket", "org.apache.zookeeper.ClientCnxnSocketNetty");
config.setProperty("zookeeper.client.secure", "true");
config.setProperty("zookeeper.ssl.keyStore.location", "/path/to/your/KeyStore.jks");
config.setProperty("zookeeper.ssl.keyStore.password", "pwd");
config.setProperty("zookeeper.ssl.trustStore.location", "/path/to/yourtruststore.jks");
config.setProperty("zookeeper.ssl.trustStore.password", "pwd");
config.setProperty("zookeeper.ssl.hostnameVerification", "false");
ZooKeeper connect = new ZooKeeper(dto.getParams().getConnectPath(), 3000, this.wh,sslcfg(dto.getParams()));9、常用命令
ZooKeeper 提供了一组命令。每个命令由四个字母组成。可以在客户端端口通过 telnet 或 nc 向 ZooKeeper 发出命令。
三个更有趣的命令:“stat”提供了有关服务器和连接的客户端的一些一般信息,而“srvr”和“cons”分别提供了有关服务器和连接的扩展详细信息。
在3.5.3开始,四个字母的单词在使用前需要明确列入白名单。有关详细信息,请参阅在集群配置中介绍过的 4lw.commands.whitelist。
| 命令 | 含义 | |
|---|---|---|
| conf | 3.3.0的新功能,打印有关服务配置的详细信息。 | |
| cons | 3.3.0 中的新功能:列出连接到此服务器的所有客户端的完整连接/会话详细信息。包括有关接收/发送的数据包数量、会话 ID、操作延迟、上次执行的操作等信息... | |
| crst | 3.3.0 中的新功能:重置所有连接的连接/会话统计信息。 | |
| dump | 列出未完成的会话和临时节点。 | |
| envi | 打印有关服务环境的详细信息 | |
| ruok | 测试服务器是否在非错误状态下运行。当白名单启用 ruok 时,服务器如果在正常运行会响应 imok ,否则根本不会响应。当 ruok 被禁用时,服务器会响应:“ruok 未执行,因为它不在白名单中。响应“imok”并不一定表示服务器已加入仲裁,只是表示服务器进程处于活动状态并绑定到指定的客户端端口。使用“stat”获取有关状态、wrt 仲裁和客户端连接信息的详细信息。 | |
| srst | 重置服务器统计信息。 | |
| srvr | 3.3.0的新功能,列出服务器的完整详细信息。 | |
| stat | 列出服务器和连接的客户端的简要详细信息。 | |
| wchs | 3.3.0 中的新功能:列出有关服务器监视的简要信息。 | |
| wchc | 3.3.0 中的新功能:按会话列出有关服务器监视的详细信息。这将输出具有关联监视(路径)的会话(连接)列表。请注意,根据此操作的监视器数量可能会很对(即影响服务器性能),请谨慎使用。 | |
| dirs | 3.5.1 中的新功能:显示快照和日志文件的总大小(以字节为单位) | |
| wchp | 3.3.0 中的新功能:按路径列出有关服务器监视的详细信息。这将输出具有关联会话的路径 (znodes) 列表。请注意,根据此操作的监视器数量可能会很昂贵(即影响服务器性能),请谨慎使用。 | |
| mntr | 3.4.0 中的新功能:输出可用于监视集群运行状况的变量列表。 | |
| isro | 3.4.0 中的新功能:测试服务器是否以只读模式运行。如果处于只读模式,服务器将响应“ro”,如果不处于只读模式,则响应“rw”。 | |
| hash | 3.6.0 中的新功能:返回与 zxid 关联的树摘要的最新历史记录。 | |
| gtmk | 以十进制格式的 64 位有符号长整型值的形式获取当前跟踪掩码。有关可能值的说明,请参阅stmk。 | |
| stmk | 设置当前跟踪掩码。跟踪掩码为 64 位,其中每个位在服务器上启用或禁用特定类别的跟踪日志记录。Logback 必须配置为TRACE级别,才能查看跟踪日志记录消息。跟踪掩码的位对应于以下跟踪日志记录类别。` |
从3.5.3版本以后,四个字母的单词将被弃用,官方建议使用AdminServer的http接口来对命令进行执行。AdminServer 是一个嵌入式 Jetty 服务器,它为四个字母的单词命令提供 HTTP 接口。默认情况下,服务器在端口 8080 上启动,并通过转到 URL “/commands/[command name]” 发出命令,例如 http://localhost:8080/commands/stat。命令响应以 JSON 格式返回。与原始协议不同,命令不限于四个字母的名称,命令可以有多个名称;例如,“STMK”也可以称为“set_trace_mask”。要查看所有可用命令的列表,请将浏览器指向 URL /commands(例如,http://localhost:8080/commands)。请参阅 AdminServer 配置选项,了解如何更改端口和 URL。
默认情况下,AdminServer 处于启用状态,但可以通过以下任一方式禁用:
- 将 zookeeper.admin.enableServer 系统属性设置为 false。
- 从类路径中删除 Jetty。(如果要覆盖 ZooKeeper 的 jetty 依赖项,此选项非常有用)。
如果通过上面的方式禁用 AdminServer,TCP 四字母字接口仍然可用。
AdminServer的Http接口如下:
| 接口 | 含义 | |
|---|---|---|
| connection_stat_reset/crst | 重置所有客户端连接统计信息。未返回任何新字段。 | |
| configuration/conf/config | 打印有关服务配置的基本详细信息,例如客户端端口、数据目录的绝对路径。 | |
| connections/cons | 关客户端与服务器连接的信息。请注意,根据客户端连接数,此操作可能会很影响服务器性能。返回“connections”,即连接信息对象的列表。 | |
| hash | 历史摘要列表中的 Txn 摘要。每 128 笔事务记录一次。返回“digests”,即事务摘要对象的列表。 | |
| dirs | 有关日志文件目录和快照目录大小(以字节为单位)的信息。返回“datadir_size”和“logdir_size”。 | |
| dump | 有关会话过期和临时的信息。请注意,根据全局会话数和临时会话数,此操作可能会很影响服务器性能)。返回“expiry_time_to_session_ids”和“session_id_to_ephemeral_paths”作为映射。 | |
| environment/env/envi | 所有定义的环境变量。将每个字段作为其自己的字段返回。 | |
| get_trace_mask/gtmk | 当前跟踪掩码。set_trace_mask 的只读版本。有关详细信息,请参阅四个字母命令 stmk 的说明。返回“tracemask”。 | |
| initial_configuration/ICFG | 打印用于启动的配置文件的文本。返回“initial_configuration”。 | |
| is_read_only/ISRO | 如果此服务器处于只读模式,则为 true/false。返回“read_only” | |
| last_snapshot/lsnp | zookeeper 服务器已完成保存到磁盘的最后一个快照的信息。如果在服务器启动和服务器完成保存其第一个快照之间的初始时间段内调用,则该命令将返回启动服务器时读取的快照信息。返回“zxid”和“timestamp”,后者使用秒的时间单位。 | |
| leader/lead | 如果集合配置为仲裁模式,则会返回当前主节点状态和当前主节点位置。返回“is_leader”、“leader_id”和“leader_ip”。 | |
| monitor/mntr | 发出各种有用的信息以供监视。包括性能统计信息、有关内部队列的信息以及数据树的摘要(以及其他内容)。将每个字段作为其自己的字段返回。 | |
| observer_connection_stat_reset/ORST | 重置所有观察者连接统计信息。观察者的配套命令。未返回任何新字段。 | |
| restore/rest | 从当前服务器上的快照输入流还原数据库。在响应负载中返回以下数据:“last_zxid”:字符串 注意:此 API 是有速率限制的(默认每 5 分钟一次),以保护服务器不会过载。 | |
| ruok | 检查服务器是否在运行。响应并不一定表示服务器已加入仲裁,只是表示管理服务器处于活动状态并绑定到指定端口。未返回任何新字段。 | |
| set_trace_mask/stmk | 设置跟踪掩码(因此,它需要一个参数)。有关详细信息,请参阅四个字母命令 stmk 的说明。返回“tracemask”。 | |
| server_stats/srvr | 服务器信息。返回多个字段,简要概述服务器状态。 | |
| stat_reset/srst | 重置服务器统计信息。这是 server_stats 和统计信息返回的信息的子集。未返回任何新字段。 | |
| observers/obsr | 有关观察者与服务器连接的信息。始终在领导者上可用,如果追随者充当学习大师,则在追随者上可用。返回“synced_observers”(int)和“observers”(每个观察者的属性列表)。 | |
| system_properties/sysp | 所有定义的系统属性。将每个字段作为其自己的字段返回。 | |
| voting_view | 提供集群中当前有投票权的成员。以地图形式返回“current_config”。 | |
| watches/wchc | 按会话汇总的watch信息。请注意,根据监视的数量,此操作可能会很影响服务器性能)。以地图形式返回“session_id_to_watched_paths”。 | |
| watches_by_path/wchp | 按路径聚合的监视信息。请注意,根据监视的数量,此操作可能会很影响服务器性能)。以地图形式返回“path_to_session_ids”。 | |
| watch_summary/wchs | 汇总的监视信息。返回“num_total_watches”、“num_paths”和“num_connections”。 | |
| zabstate | 对等节点正在运行的 Zab 协议的当前阶段,以及它是否是投票成员。对等方可以处于以下阶段之一:选举、发现、同步、广播。返回字段“voting”和“zabstate”。 | |
六、常见问题
以下是正确配置 ZooKeeper 可以避免的一些常见问题。
1、服务器列表不一致
服务器列表不一致* :客户端使用的 ZooKeeper 服务器列表必须与每个 ZooKeeper 服务器拥有的 ZooKeeper 服务器列表匹配。如果客户端列表是真实列表的子集,那么事情就可以正常工作,但是如果客户端具有位于不同 ZooKeeper 集群中的 ZooKeeper 服务器列表,则事情会变得非常奇怪。此外,每个 Zookeeper 服务器配置文件中的服务器列表应彼此一致。
2、事务日志放置不正确
ZooKeeper 对性能最关键的部分是事务日志。ZooKeeper 在返回响应之前将事务同步到持久化的介质。专用事务日志设备是实现稳定良好性能的关键。将日志放在繁忙的设备上会对性能产生负面影响。如果只有一个存储设备,请增加 snapCount,以便减少生成快照文件的频率;它不能消除问题,但它为事务日志提供了更多资源。
3、不正确的 Java 堆大小
应该特别注意正确设置 Java 最大堆大小。特别是,不应创建 ZooKeeper 交换到磁盘的情况。磁盘对 ZooKeeper 来说是死亡。一切都是有序的,因此,如果处理一个请求交换磁盘,则所有其他排队的请求可能会执行相同的操作。磁盘。不要交换。保守估计:如果有 4G 的 RAM,请不要将 Java 最大堆大小设置为 6G 甚至 4G。例如您更有可能将 3G 堆用于 4G 计算机,因为操作系统和缓存也需要内存。估计系统所需的堆大小的最佳且唯一推荐的做法是运行负载测试,然后确保远低于会导致系统交换的使用限制。
4、可公开访问的部署
ZooKeeper 集群应在受信任的计算环境中运行。因此,建议将 ZooKeeper 部署在防火墙后面。
5、不正确的集群实例个数
集群模式(包括伪集群模式,即在一台服务器上部署多个 ZooKeeper 进程)下,遵循 “过半存活即可用” 的原则:
ZooKeeper 集群中,建议部署奇数个 ZooKeeper节点(或进程) —— 大多数情况下,3个节点就足够了。
节点个数并不是越多越好 —— 节点越多,节点间通信所需的时间就会越久,选举 Leader 时需要的时间也会越久。
ZooKeeper 集群中,在保证集群可用的前提下,最多允许挂掉的节点个数,即为 ZooKeeper 集群的容错数,也叫集群的容忍度。
为了集群中 Leader 节点的选举,允许挂掉的节点个数 < 剩余的存活节点个数 —— 剩余的存活节点个数必须大于n/2,n为总节点个数。
2n 和 2n-1(n>1) 个节点的集群的容错数都是 n-1。比如:
5个节点中,最多允许挂掉2个,因为剩余的3个节点大于5/2;
6个节点中,最多允许挂掉2个,因为剩余的4个节点大于6/2为什么不能是偶数个节点?
- 防止由脑裂造成的集群不可用
(1) 假如:集群有 5 个节点,发生了脑裂,脑裂成了 A、B 两个小集群:
(a) 小集群 A:1个节点,小集群 B:4个节点,或A、B互换
(b) 小集群 A:2个节点,小集群 B:3个节点,或A、B互换上面两种情况下,A、B 中总会有一个小集群满足 可用节点数量 > 总节点数量/2 ,所以集群仍然能选举出 leader,仍然能对外提供服务。
(2) 假如:集群有4个节点,同样发生脑裂,脑裂成了 A、B 两个小集群:
(a) 小集群 A:1个节点,小集群 B:3个节点,或 A、B互换
(b) 小集群 A:2个节点,小集群 B:2个节点上述情况 (a) 满足选举条件,而情况(b)不满足,此时集群就彻底不能提供服务了。
- 奇数个节点更省资源
原则上 ZooKeeper 集群中可以有偶数个节点,但其容错数并不会提高,反而降低了集群间的通信效率,也浪费了资源。
6、脑裂现象
ZooKeeper 集群中,各个节点间的网络通信不良时,容易出现脑裂(split-brain)现象。
1)集群中的部分 follower 节点监听不到 leader 节点的心跳,就会认为 leader 节点出了问题;
2)这些监听不到 leader 节点心跳的 follower 节点就会选举出新 leader 节点;
3)新的 leader 和旧 leader 节点 和各自的 follower 节点组成多个小集群。
—— 一个集群中有多个 leader 节点,这就是脑裂现象。
通常的解决思路就是:集群中节点个数控制在奇数个,而不是偶数。
七、参考资料
八、结束语
ZooKeeper 已成功应用于许多工业应用。它在雅虎 用作 Yahoo! Message Broker 的协调和故障恢复服务,Yahoo! Message Broker 是一个高度可扩展的发布-订阅系统,用于管理数千个用于复制和数据传输的主题。它由Fetching Service for Yahoo!爬网程序使用,它还管理故障恢复。许多雅虎广告系统也使用ZooKeeper来实现可靠的服务。
如果你是在大公司做开发,zookeeper一般有专门的运维人员维护,普通开发人员无需关心。如果你是在小公司的话,zookeeper绝对要会基本操作的!相信看完本文的你,和小郭一样对Zookeeper有了基本的认识。